作为一个应用管理和集成平台,在生产环境中,KubeVela 需要处理数以千计的应用。 为了评估 KubeVela 的性能,开发团队基于模拟环境进行了性能测试,并展示了同时管理大量应用的能力。
设置
集群环境
使用大型集群需要大量资源,例如机器、网络带宽、存储和许多其他设备。 因此,KubeVela 团队采用 kubernetes 官方提供的工具 kubemark,通过 mock 数百个 kubelet 来模拟大型集群。 每个 kubelet 都像一个真实的节点一样工作,只是它们不在 pod 内运行真实的容器。 KubeVela 性能测试的目的主要是关注 KubeVela 控制器是否能够有效地管理数以千计的应用,而不需要拉取镜像或者在 pod 中执行命令。 因此,我们只需要获取托管在这些假节点(也称为空心节点)上的资源。
我们在阿里云上搭建了 Kubernetes 集群,包括 5 个 master 节点和 15 个 worker 节点。 master 节点将托管 Kubernetes 核心组件,例如 kube-apiserver 和 kube-controller-manager。 worker 节点需要运行其他与压力测试相关的组件,包括监控工具、KubeVela 控制器和 kubemark pod。 由于主要目标是测试 KubeVela 控制器的性能,我们预计其他组件不会成为压力测试的瓶颈。 为此,master 节点和 worker 节点都配备了 32 核和 128 Gi 内存。 我们使用 Prometheus、Loki 和 Grafana 的组合作为监控套件,并为它们提供足够的资源以避免内存不足导致的崩溃。
请注意,KubeVela 控制器和监控工具需要放置在真实节点上才能运行,而在性能测试期间创建的所有 pod 都应正确分配给空心节点。 为此,我们为空心节点和真实节点赋予不同的污点,并为不同的 pod 添加相应的容忍度。
应用
为了模拟生产环境中的真实应用,我们设计了一个包含 2 个组件和 5 个 trait 的应用模板,包括:
- 一个 webservice 组件
- 一个 scaler trait 设置副本数是 3
- 一个 sidecar trait 为每个 pod 附加另一个容器
- 一个 ingress trait 生成一个 ingress 实例和一个 service 实例
- 一个 worker 组件
- 一个 scaler trait 同样设置副本数是 3
- 一个 configmap trait 生成一个新的 configmap 并将它附加到工作 pod
在下面的实验中,我们测试了 KubeVela 控制器在 200 个节点上管理 3,000 个应用(总共 12,000 个 Pod)的性能。 应用最初是并行创建的,然后保持运行一段时间,最后从集群中删除。 每个应用都将进行多次调和,消耗监控工具记录的资源。
实践中,我们还有另一个用于添加上述容忍度的 trait。
KubeVela 控制器
KubeVela 控制器使用如下的一组推荐配置:
- Kubernetes Resource
- 0.5 核 CPU
- 1 Gi 内存
- 单副本
- Program
- concurrent-reconciles=2 (reconcile 线程数)
- kube-api-qps=300 (控制器中使用的 kubernetes 客户端的 qps)
- kube-api-burst=500 (控制器中使用的 kubernetes 客户端的峰值)
- informer-re-sync-interval=20m (定时调和的间隔.)
我们将在后面的章节中分析这些设置。
为了评估 KubeVela 控制器本身的性能,我们禁用了 Ingress MutatingWebhook 和 Application ValidatingWebhook,这超出了本次测试的重点,但会通过增加创建/修补资源的延迟来影响 KubeVela 控制器的性能。
实验
创建
创建所有 3,000 个应用耗时 25 分钟。 让所有 pod 运行需要更长的时间,这超出了 KubeVela 控制器的范畴。
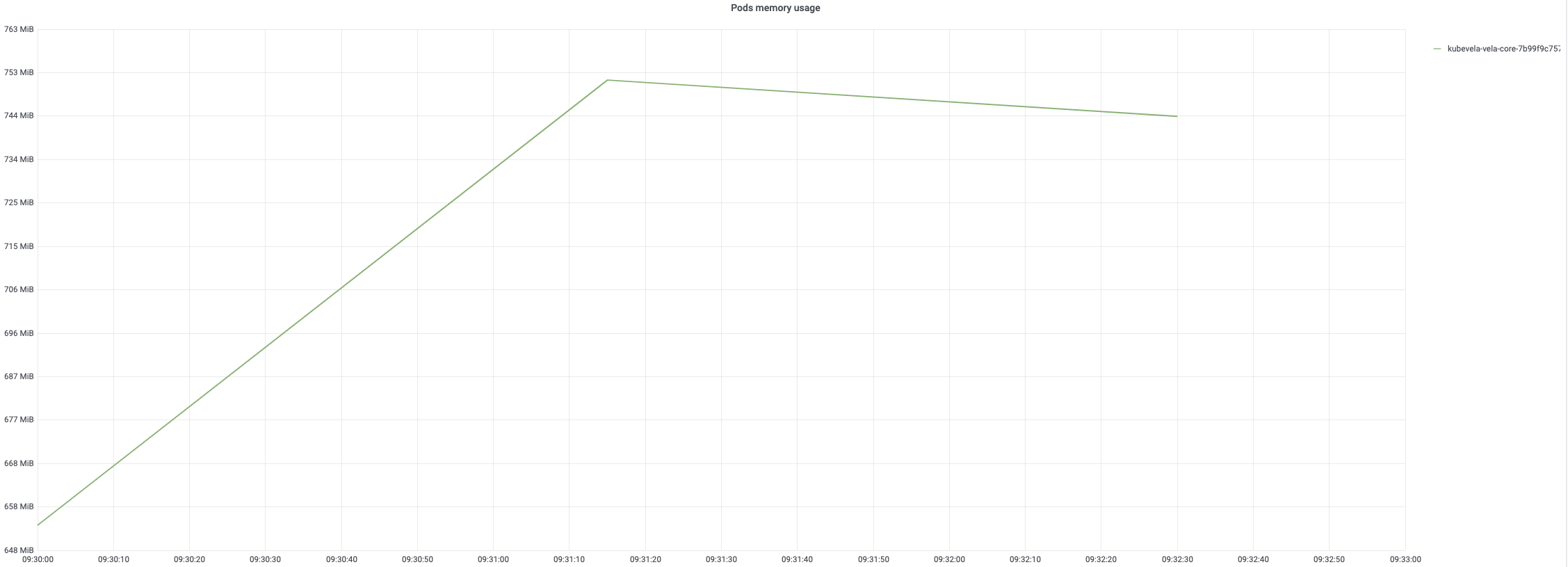
每个应用的创建将触发三轮调和。 创建后期CPU使用率会达到100%。内存使用量将随着应用数量的增加而增加。创建结束时达到约 67%。
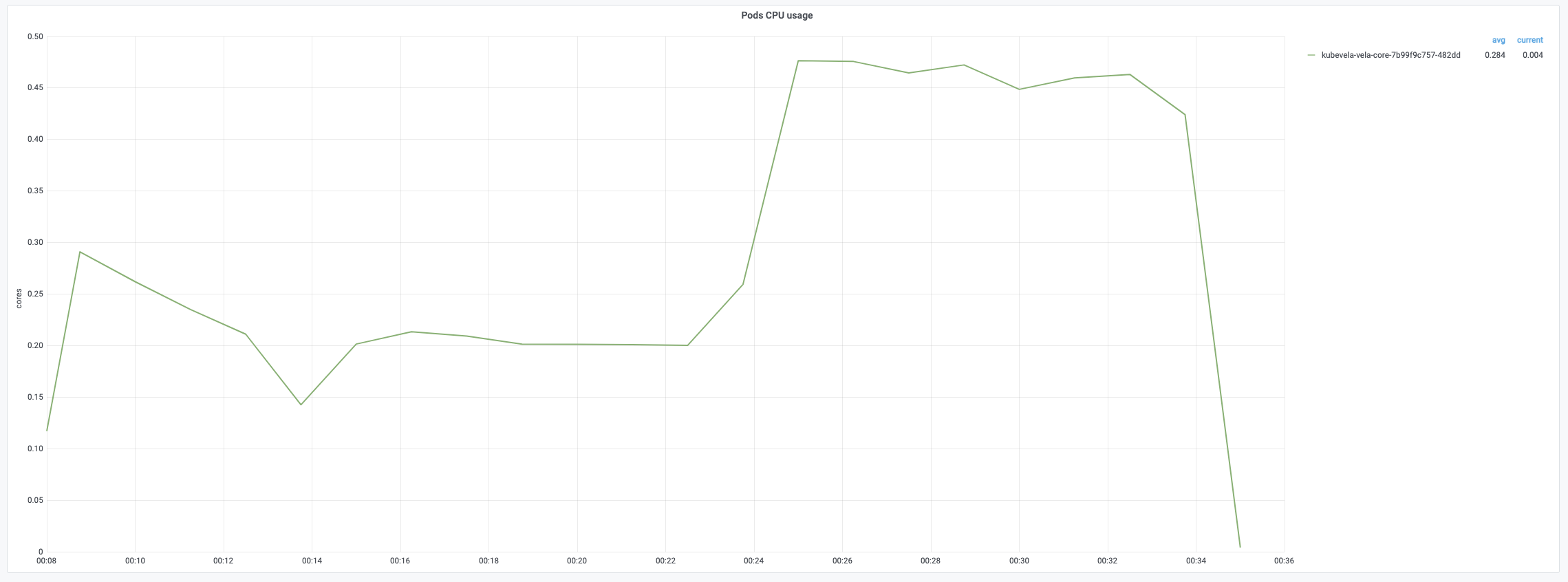
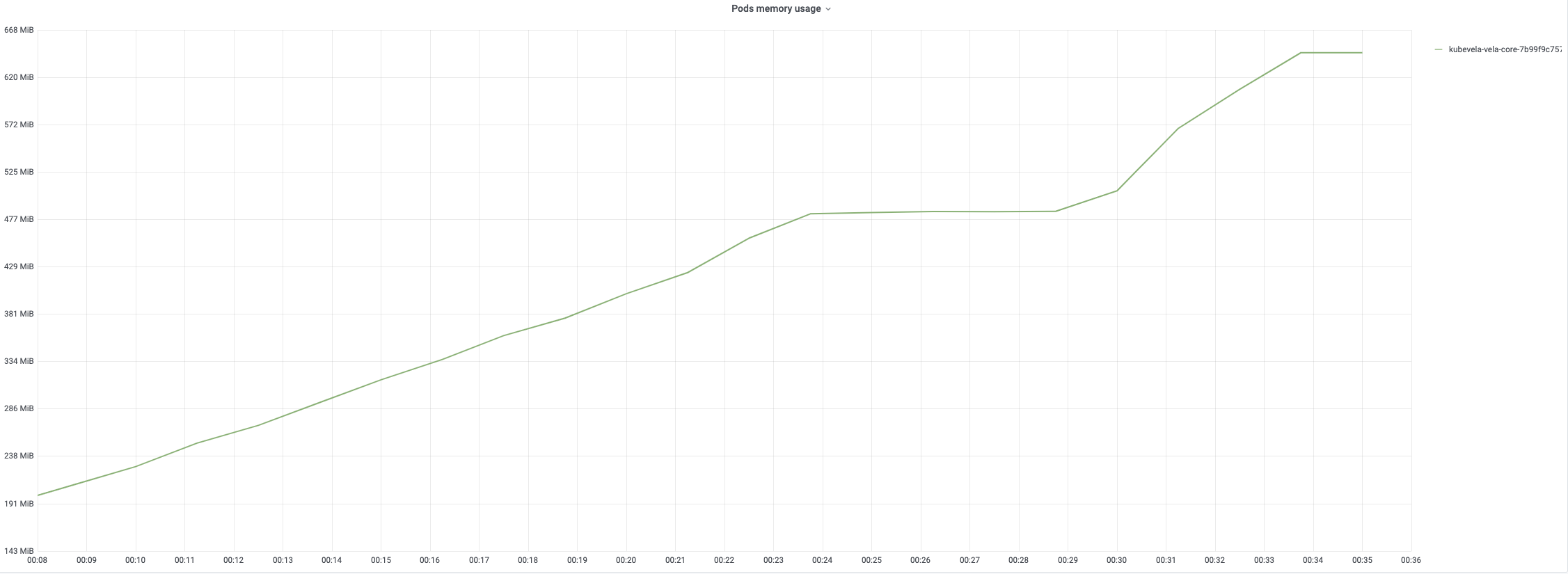
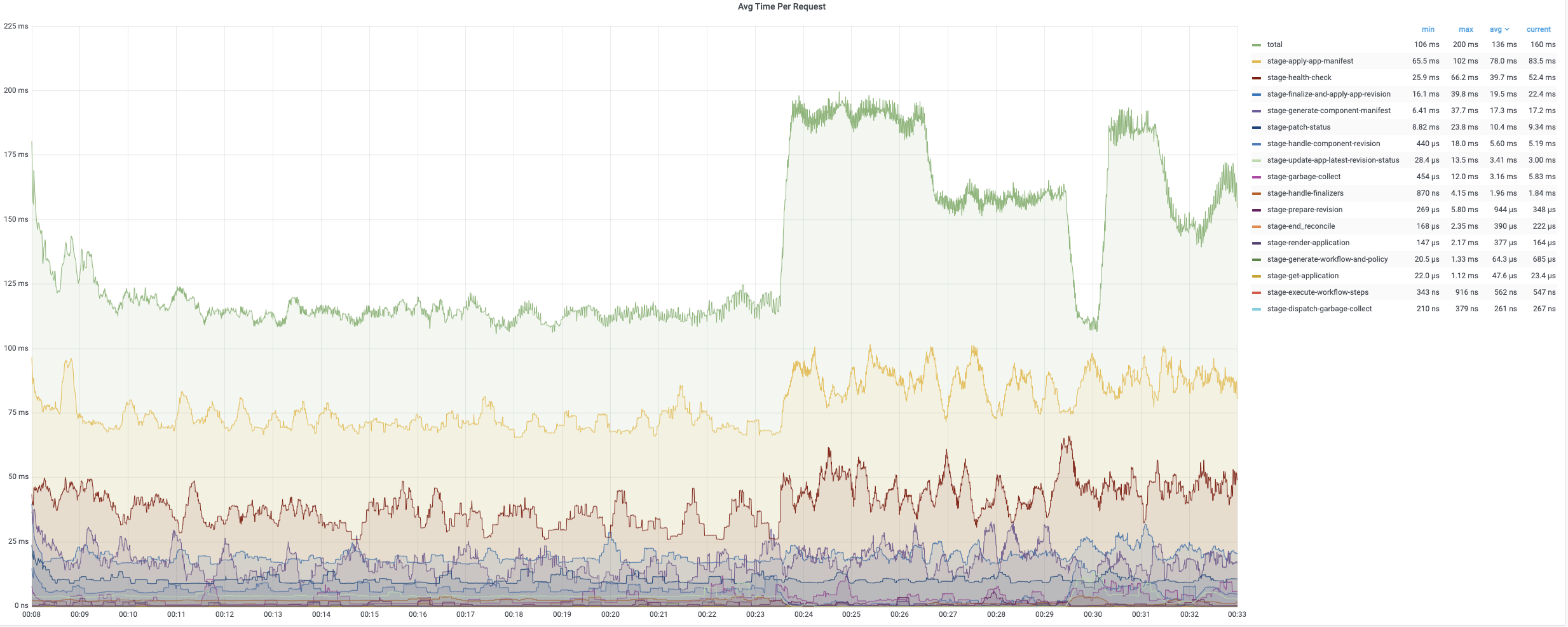
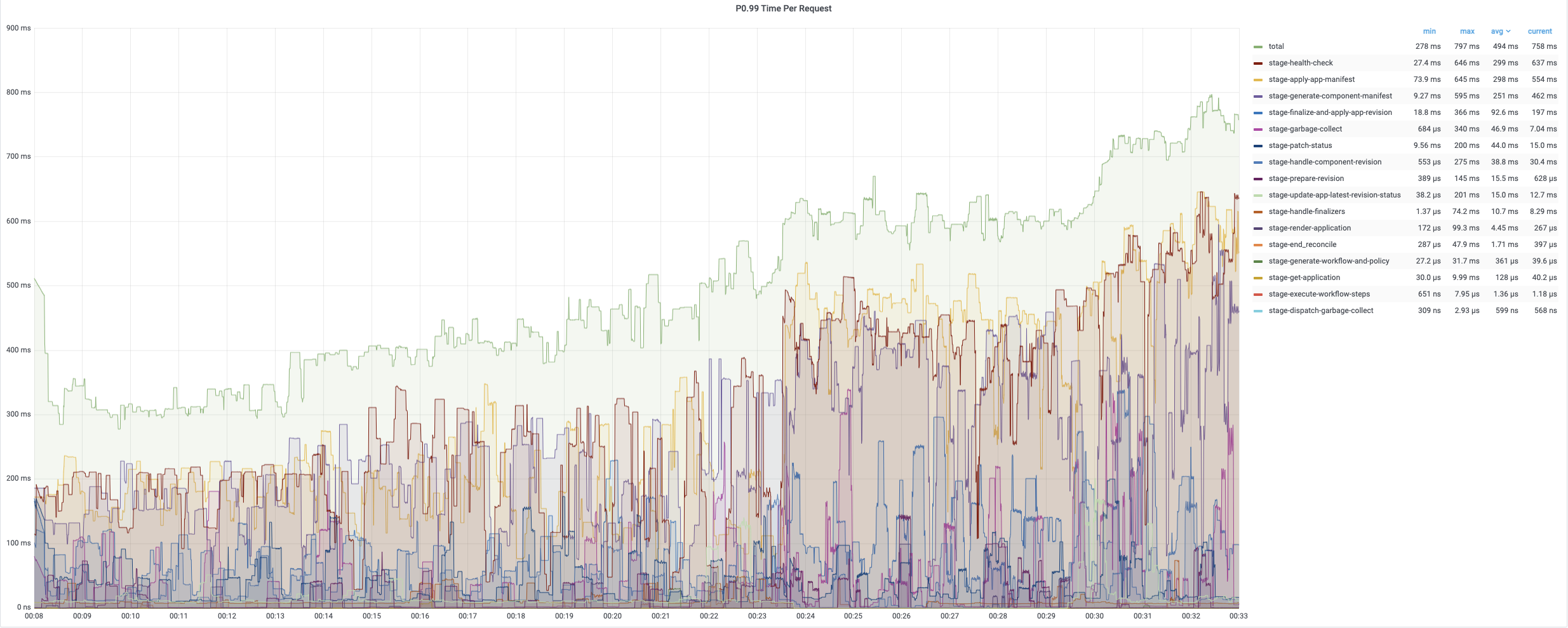
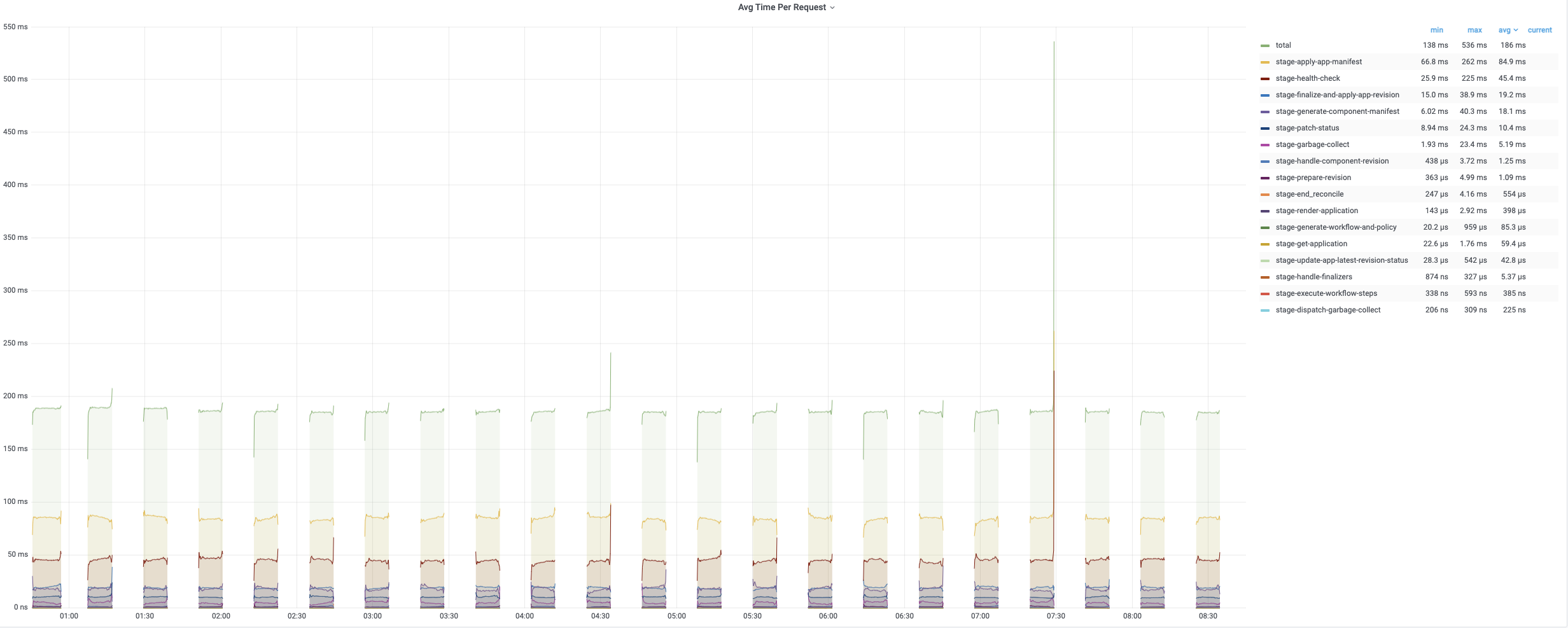
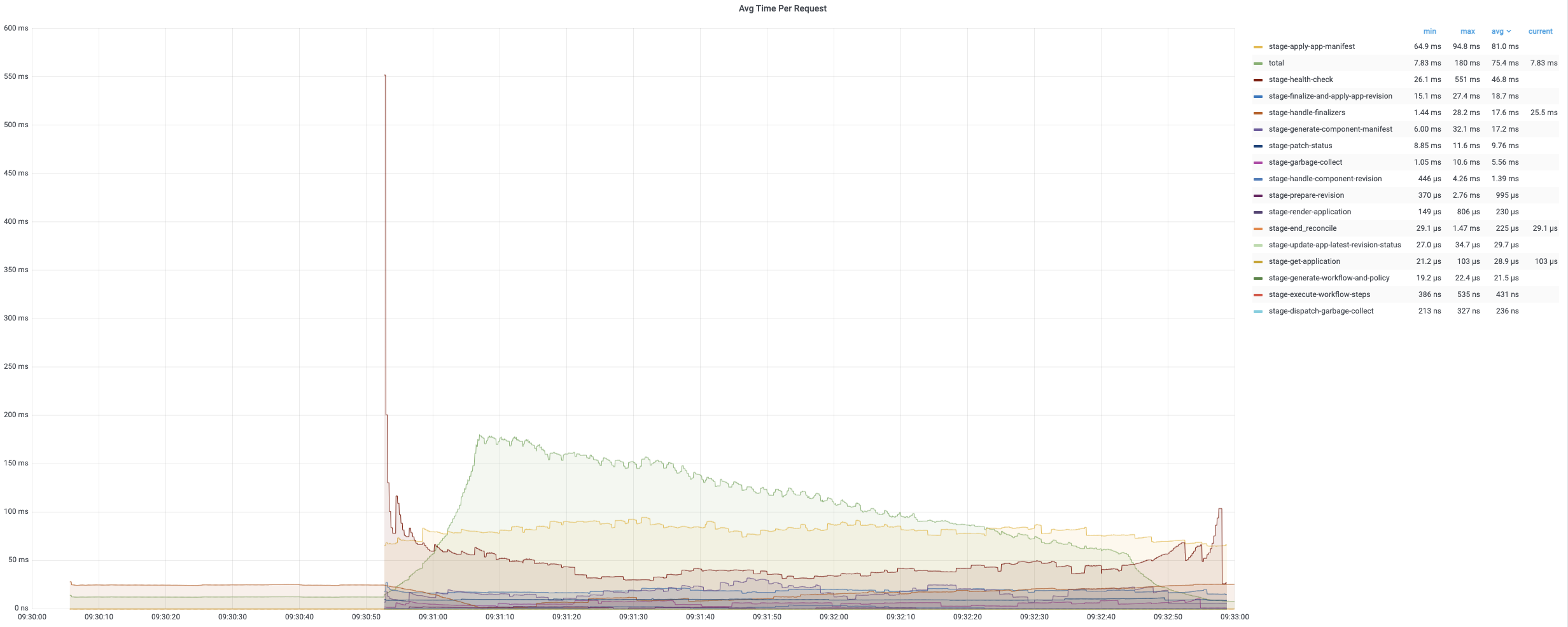
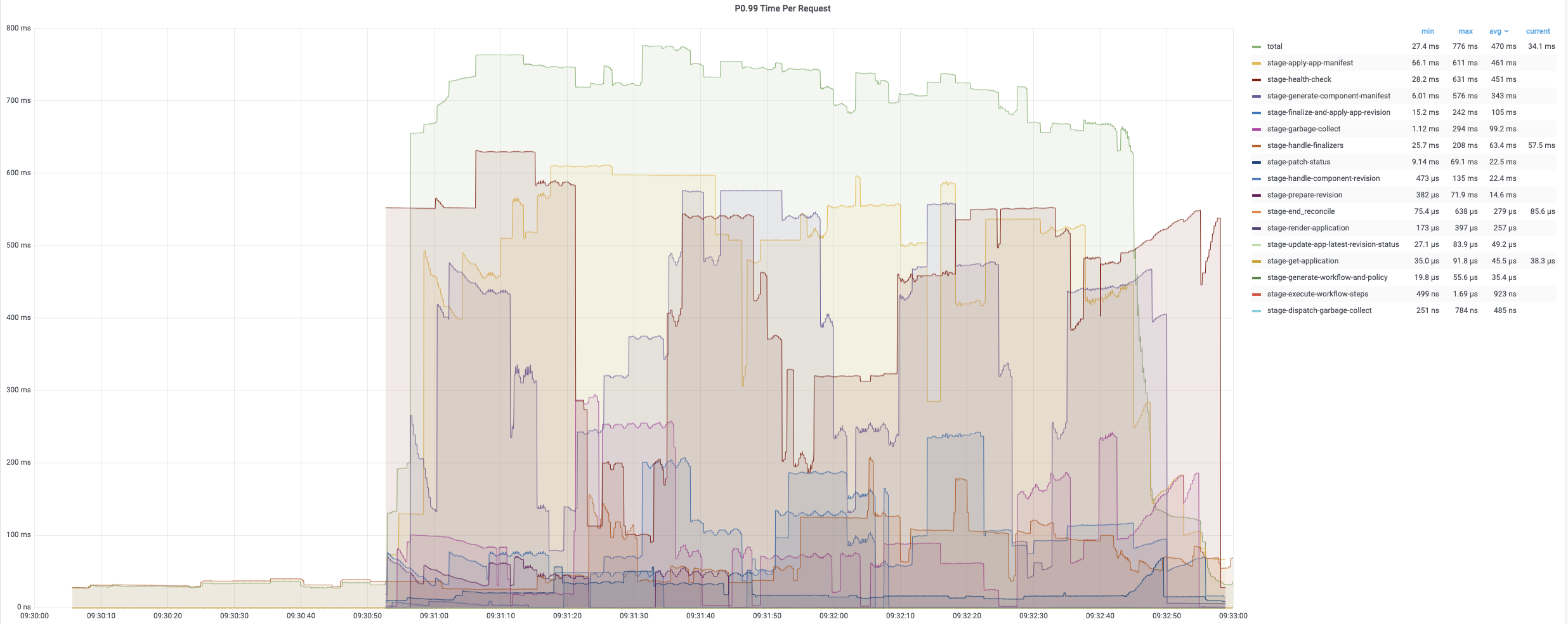
第一轮调和的平均时间相对较短,因为它只需要添加 finalizer。 第二轮和第三轮调和包含完整的调和循环,需要更多时间来处理。 以下图表记录了调和应用期间不同时期的时间消耗。 平均时间通常低于 200 毫秒,而 99% 的调和少于 800 毫秒。
定时调和
创建后,控制器每 20 分钟调和一次应用。8 小时调和过程的监控如下图所示。 一旦开始定期调和,CPU 使用率将达到 90%。 内存使用量一般保持稳定模式,内存使用率最高可达 75%。
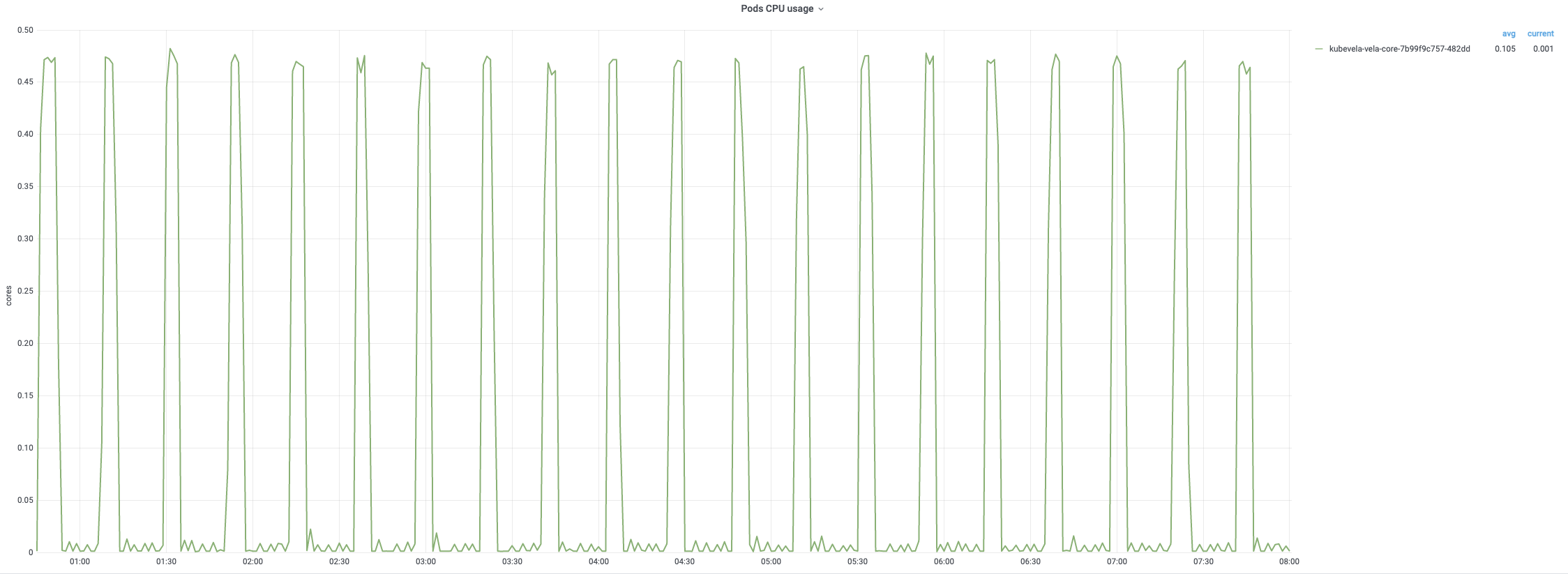
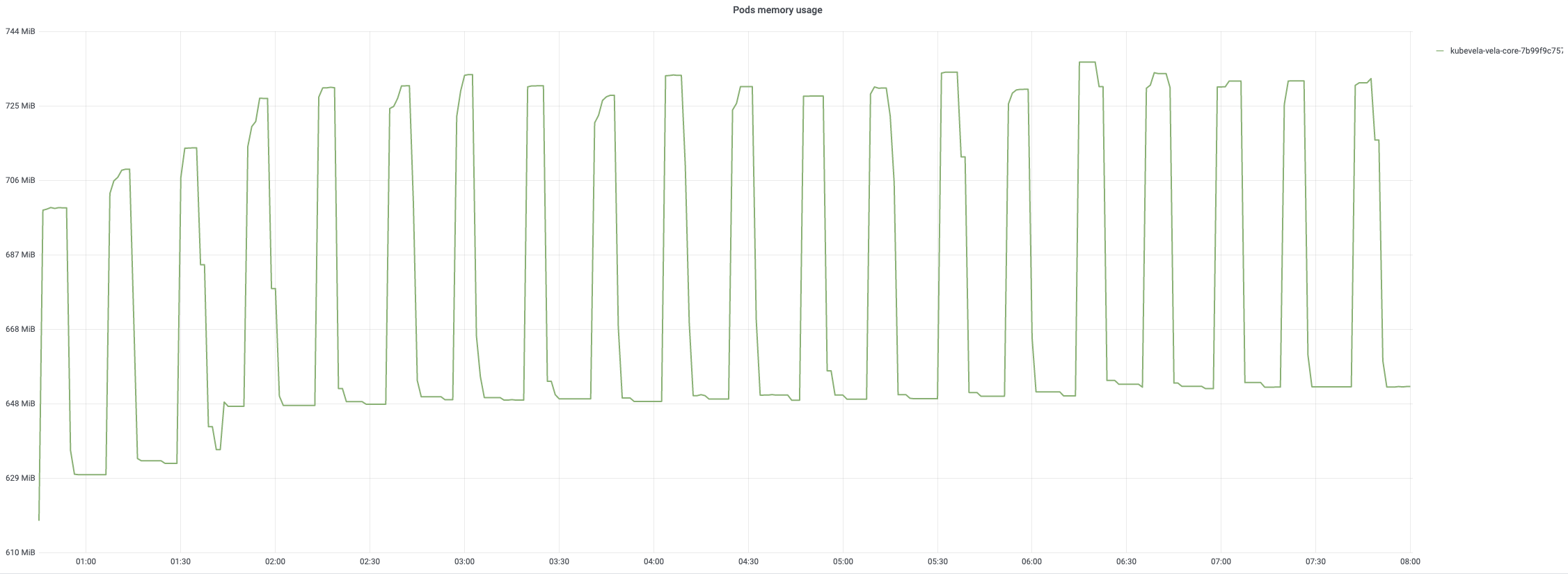
平均协调时间在 200 毫秒以下,而 99% 约为 800 毫秒~900 毫秒。 所有应用的每次定时调和通常需要大约 10 分钟。

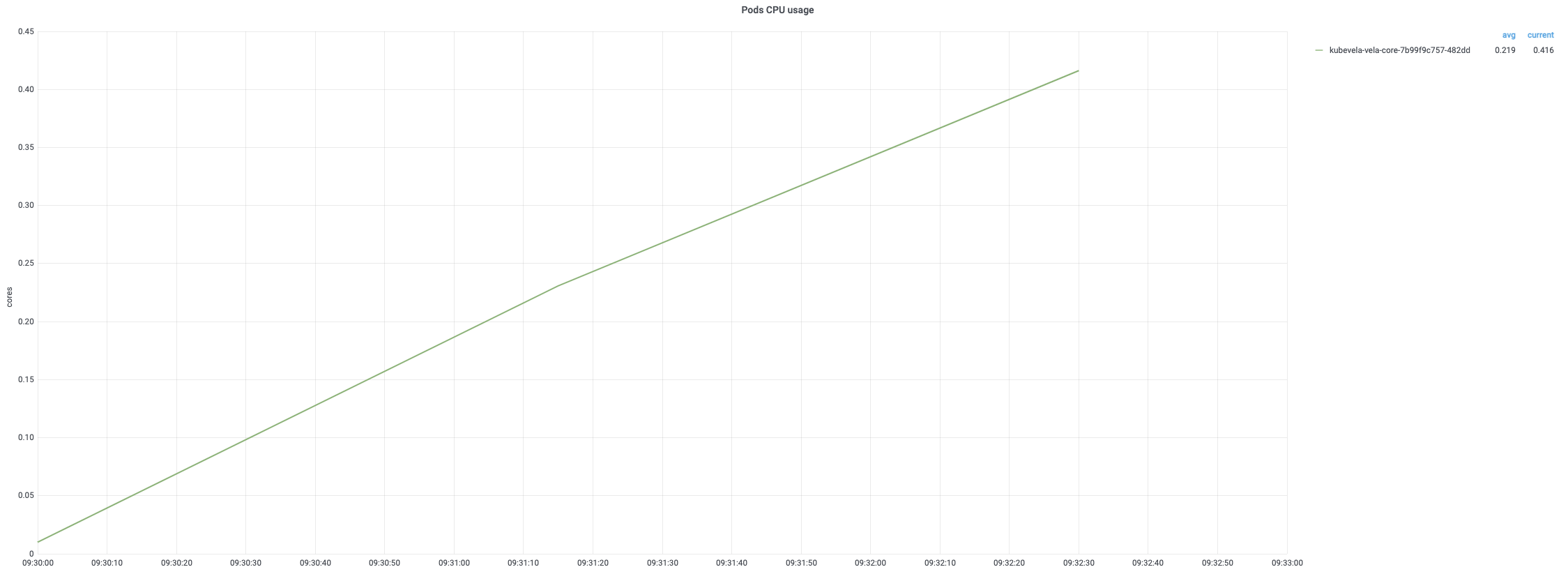
删除
应用删除过程很快并且资源消耗低。 删除所有应用只需不到 3 分钟。 但是,请注意,删除由应用管理的资源通常需要更长的时间。因为这些资源(例如 deployment 或 Pod)的清理不是由 KubeVela 控制器直接控制的。KubeVela 控制器负责删除它们的所有者并通过触发级联删除来清理它们。 此外,每次删除都关联两轮调和,其中第二轮在检索目标应用失败时立即返回(因为它已被删除)。
分析
应用数
上面的实验演示了 KubeVela 的经典场景。虽然在这种情况下,KubeVela 控制器成功管理了 3000 个应用,但强烈建议在上述配置下采用较小数量的(例如 2000 个)应用,原因如下: 时间和资源消耗与应用的规格密切相关。 如果很多用户使用更大的应用、更多的 pod 和更多的其他资源,3000 个应用可能更容易突破资源限制。 上面显示的内存和 CPU 使用率接近资源限制。 如果内存耗尽,KubeVela 控制器将崩溃并重新启动。 如果长时间保持高 CPU 使用率,可能会导致 KubeVela 控制器中的等待队列过长,进而导致变更应用的响应时间更长。
配置
用户可以配置几个参数以适配他们自己的场景。为 KubeVela 控制器使用更多副本不会扩大 KubeVela 控制器的能力。 leader 选举机制确保只有一个副本可以工作,而其他副本将等待。 多副本的目的是在主副本崩溃时能够快速恢复。 但是,如果是由 OOM 引起的崩溃,那么通常将无法修复。 在扩展 KubeVela 控制器时,应相应增加程序配置中的 qps 和 burst 的值。 这两个参数限制了控制器向 apiserver 发送请求的能力。 一般来说,为了扩大 KubeVela 控制器,扩大资源限制和上面提到的所有程序参数(除了调和间隔)。 如果你有更多应用需要管理,请添加更多内存。 如果你有更高的操作频率,增加更多的 CPU 和线程,然后相应地增加 qps 和 burst。 更长的调和间隔允许处理更多的应用,但代价是修复潜在的底层资源问题的时间更长。 例如,如果一个应用管理的 deployment 消失了,定时调和可以发现这个问题并修复它。
扩展
除了上述实验之外,我们还进行了另外两个实验来测试 KubeVela 控制器如何扩展到更大的集群和更多的应用。
在一个 500 节点的集群中,我们尝试以每秒 4 个的速度创建 5,000 个具有上述相同规格的应用,持续时间约为 21 分钟。 KubeVela 控制器使用 4 个并发调和线程,1 核 CPU 和 2Gi 内存。 kube-api-qps 和 kube-api-burst 相应地提高到 500/800。 所有 30,000 个 pod 都成功进入运行阶段。 每次调和的时间成本与之前的实验相似,相较于给定的资源,CPU/内存成本不是很高。 5,000 个应用的定时调和需要 7~8 分钟,并且没有发现显著的资源消耗。 在这个扩展过程中,我们发现 kube-apiserver 的吞吐量开始阻塞应用的创建,因为在提交应用时需要创建太多的资源。


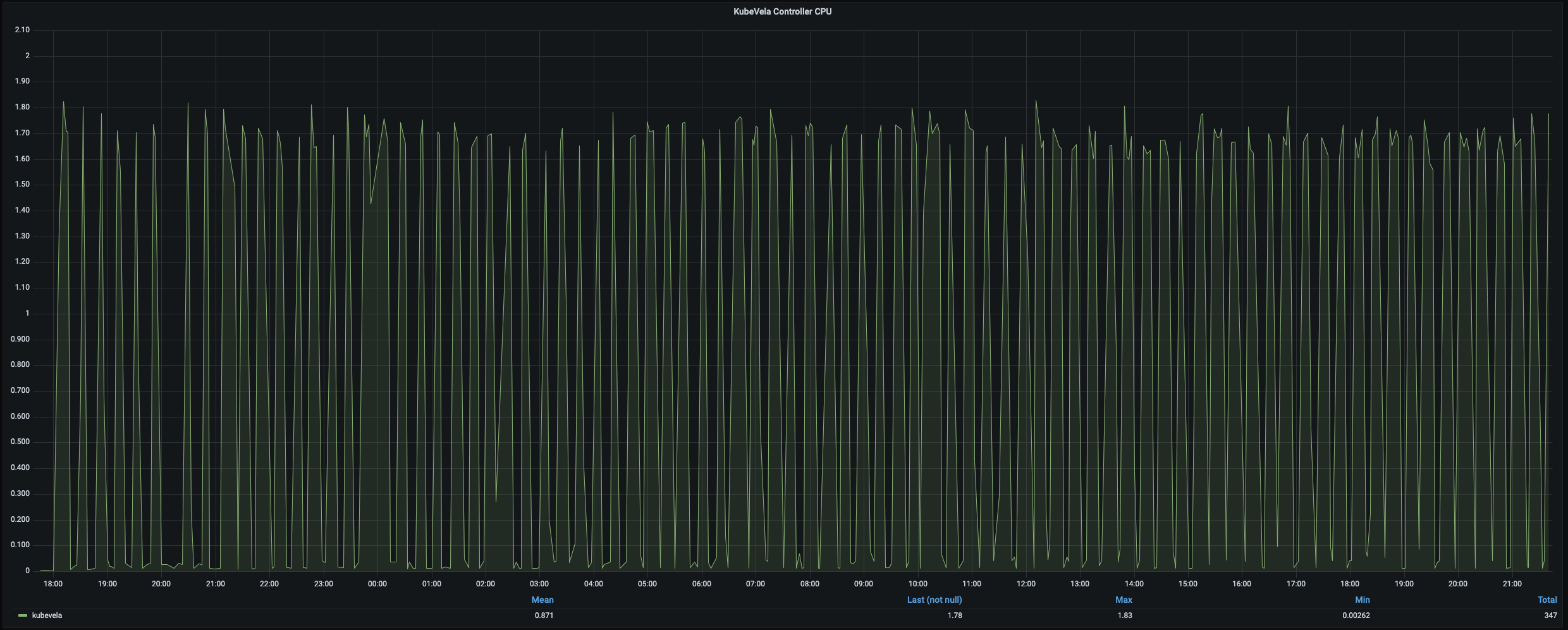
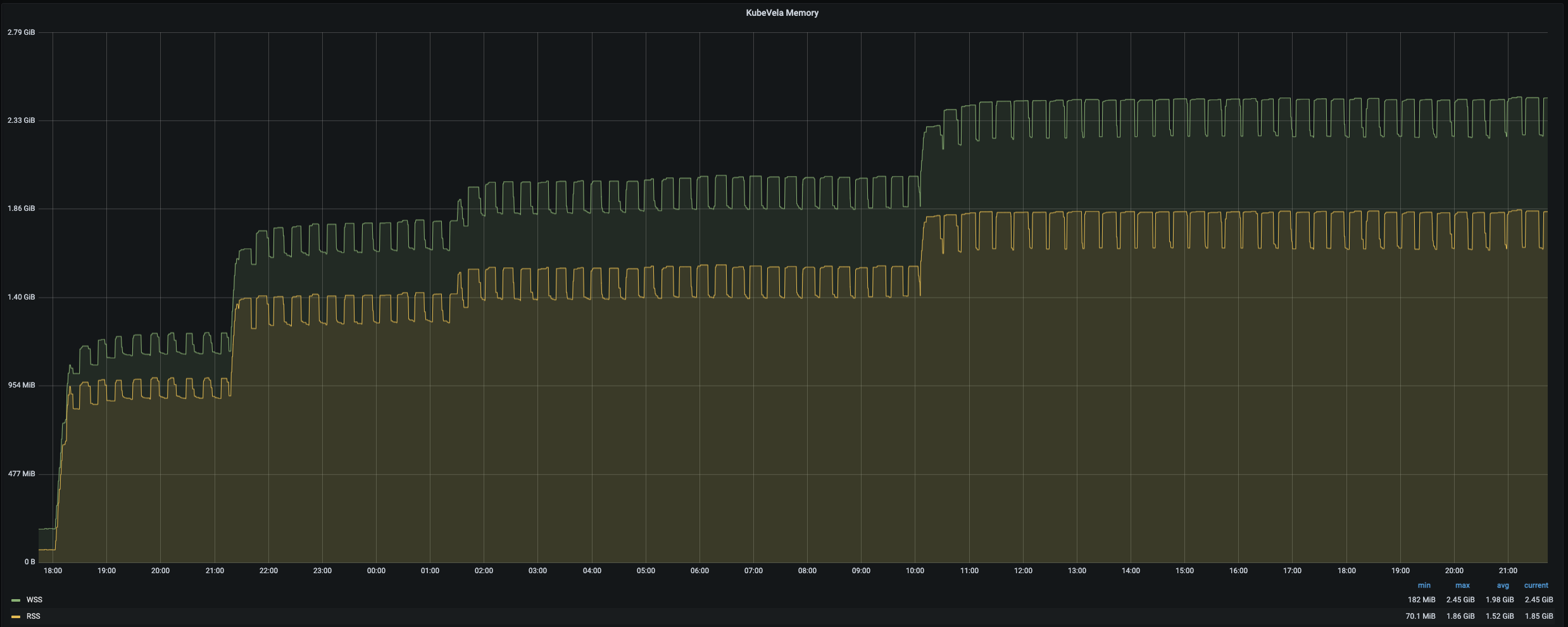
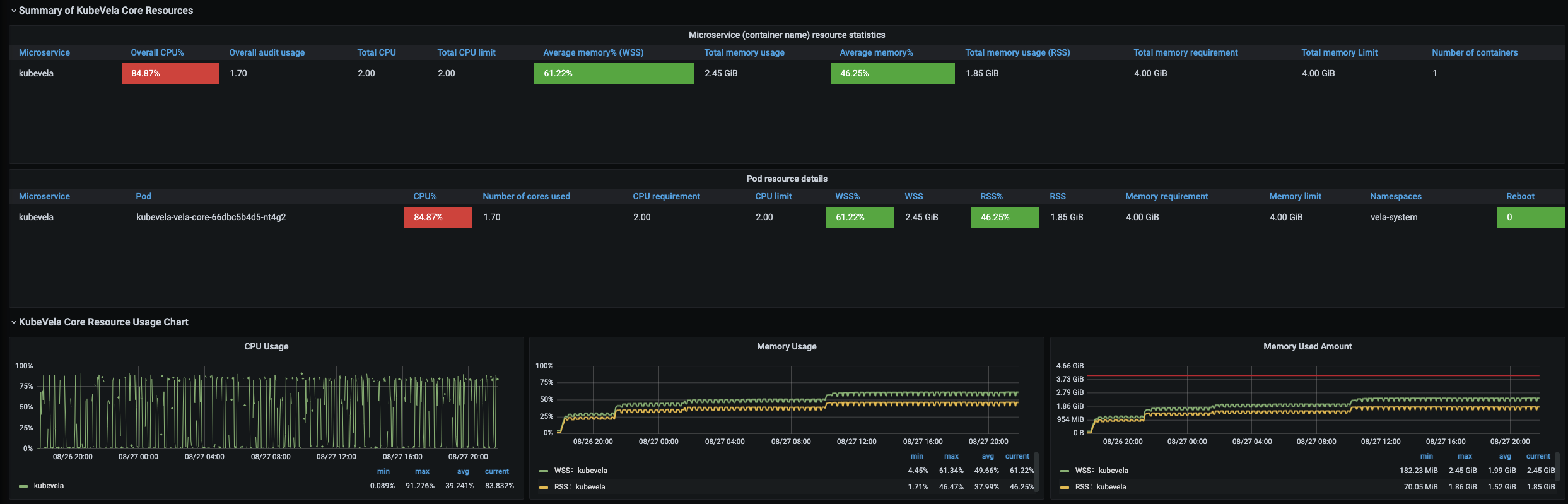
在 1,000 个节点上扩展到 12,000 个应用比先前的实验要难得多。同样的创建速度,apiserver 会被大量的 pod 调度请求淹没,最终开始丢弃创建应用的请求。为了克服这个困难,我们将应用的创建过程分为几个阶段。 每个阶段只创建 1,000~3,000 个应用,并且在所有 pod 都准备好之前不会开始下一个阶段。 通过这种策略,我们成功创建了 12,000 个应用、24,000 个 deployment、12,000 个 service 、12,000 个 ingress、12,000 个 configmap 和 72,000 个 Pod。 整个过程大约需要30个小时。 为了管理这些应用,KubeVela 控制器消耗了 1.7 核 CPU 和 2.45Gi 内存。 完成所有 12,000 个应用的一整轮定时调和大约需要 12 分钟。
展望
KubeVela 的性能测试证明了其以有限的资源消耗管理数千个应用的能力。它还可以在具有 1,000 个节点的大型集群上扩展到超过 10,000 个应用。 此外,KubeVela 团队还对 OpenKruise 中的 CloneSet 等不是基于 deployment 的应用进行了类似的压力测试(未包含在本报告中),并得出了相同的结论。 未来,我们将为更复杂的场景(如 Workflow 或 MultiCluster)添加更多性能测试。