
在应用交付中另一个很大的诉求是对资源交付流程的透明化管理,比如社区里很多用户喜欢使用 Helm Chart ,把一大堆复杂的 YAML 打包在一起,但是一旦部署出现问题,如底层存储未正常提供、关联资源未正常创建、底层配置不正确等,即使是一个很小的问题也会因为整体黑盒化而难以排查。尤其是在现代混合的多集群混合环境下,资源类型众多、错综复杂,如何从中获取到有效信息并解决问题是一个非常大的难题。
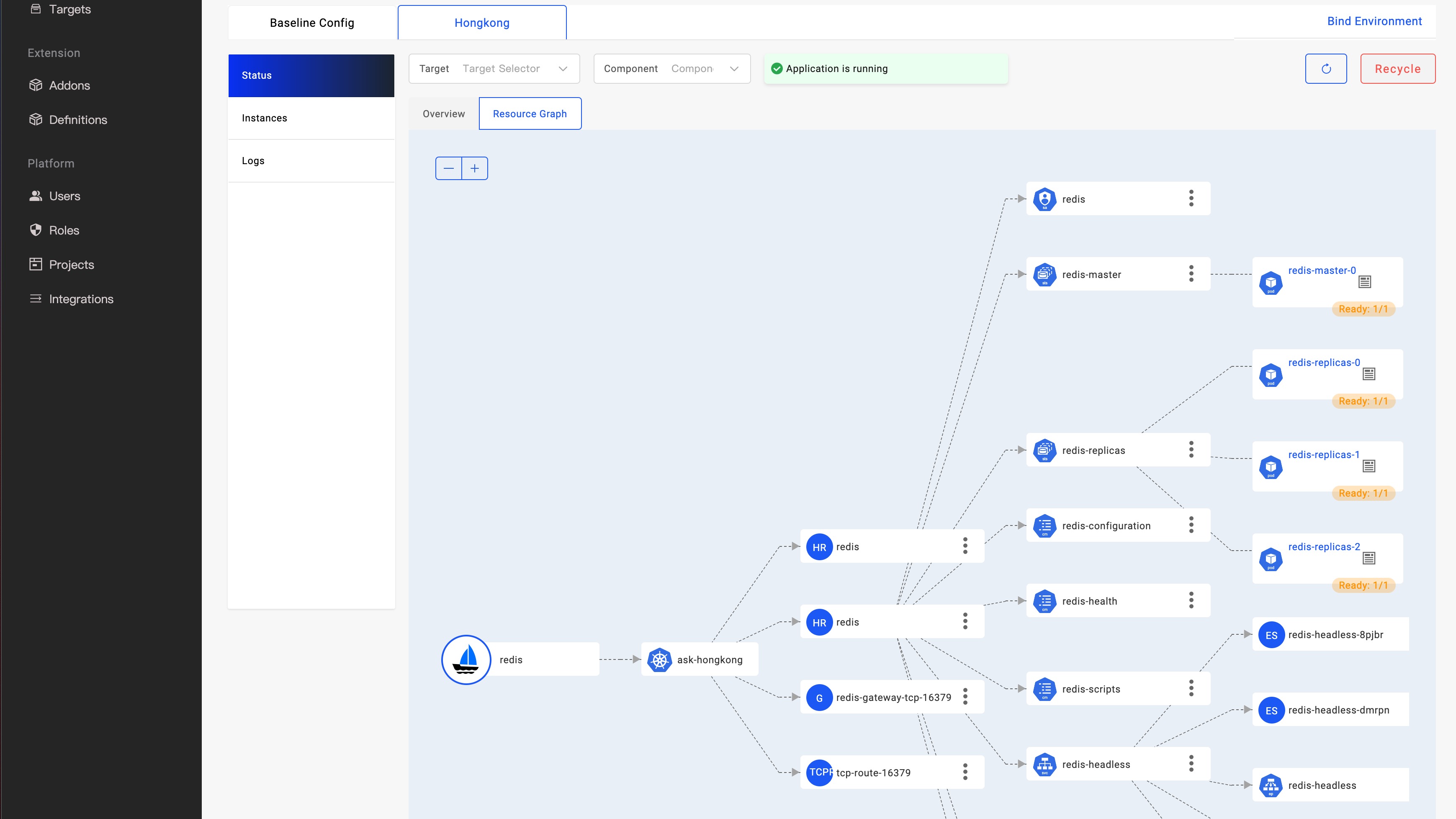
如上图所示,KubeVela 已经发布了针对应用的实时观测资源拓扑图功能,进一步完善了 KubeVela 以应用为中心的交付体验。开发者在发起应用交付时只需要关心简单一致的 API ,需要排查问题或者关注交付过程时,可以通过资源拓扑功能,快速获取资源在不同集群的编排关系,从应用一直追踪到 Pod 实例运行状态,自动化地获取资源的关联关系,包括复杂且黑盒化的 Helm Chart。
在本篇文章中,我们将介绍 KubeVela 的这项新能力是如何实现和工作的,以及后续的迭代方向。
应用的资源构成
在 KubeVela 中,应用由多个组件,运维特征组成,同时关联交付工作流和交付策略配置,应用配置通过渲染/检验等流程生成了 Kubernetes 资源,下发到目标集群。以一个简单的应用为例:
apiVersion: core.oam.dev/v1beta1
kind: Application
metadata:
name: first-vela-app
spec:
components:
- name: express-server
type: webservice
properties:
image: oamdev/hello-world
ports:
- port: 8000
expose: false
基于上述配置,实际会渲染出来一个 Deployment 资源部署到目标集群, 如果我们稍微增加一些配置,比如:
apiVersion: core.oam.dev/v1beta1
kind: Application
metadata:
name: first-vela-app
spec:
components:
- name: express-server
type: webservice
properties:
image: oamdev/hello-world
ports:
- port: 8000
expose: true
traits:
- type: gateway
properties:
domain: testsvc.example.com
http:
"/": 8000
上述配置我们将 8000 端口的 expose 属性设置为true,同时添加了一个类型为 gateway 类型的运维特征,该应用实际会渲染出 Deployment + Service + Ingress 三个资源。
如上所述,由应用直接渲染出来的资源我们称为 直接资源 ,它们将同时存储于 ResourceTracker 中作为版本记录,这些资源我们可以直接索引获得。当这些资源被下发到目标集群后,以 Deployment 资源为例, 将产生下级资源 ReplicaSet 进而再衍生下级资源 Pod。这些由直接资源二次衍生出来的资源称为 间接资源。完整的应用资源树由直接资源和间接资源构成,他们都是支撑应用运行的关键环节。
应用资源关系
上一章节中描述的 Deployment =》 ReplicaSet =》Pod 这条关系链就是资源级联关系,这也是 Kubernetes 系统的入门知识,我们通过经验可以非常容易构建这条关系链。其中 Deployment 为直接资源,我们可以从根据(应用&组件&集群)条件索引到该资源。接下来我们主要分析间接资源关系的建立。
在 Kubernetes 中,为了记录资源间的关系设计了 属主引用(Owner Reference)概念。比如下面这个用例,Pod 资源记录了其父级资源 ReplicaSet。
apiVersion: v1
kind: Pod
metadata:
name: kruise-rollout-controller-manager-696bdb76f8-92rsn
ownerReferences:
- apiVersion: apps/v1
blockOwnerDeletion: true
controller: true
kind: ReplicaSet
name: kruise-rollout-controller-manager-696bdb76f8
uid: aba76833-b6e3-4231-bf2e-539c81be9278
...
因此理论上我们可以通过资源的 Owner Reference 来反向建立任何资源依赖链路。然而这里会有两个难点:
- 我们经验中的资源链路却并不一定能通过 Owner Reference 来构建,比如 HelmRelease 资源,这是 FluxCD 定义的交付 Helm Chart 包的资源 API。在 KubeVela 中,我们使用此 API 来交付 Helm Chart 制品。 Helm Chart 理论上可以包括任何 Kubernetes 集群资源类型,从用户经验认知来说,这些资源都是 HelmRelease 的下级资源,但是目前 HelmRelease 无法作为这些资源的 Owner。也就是说如果我们无法通过 Owner Reference 来建立类似 HelmRelease 资源的追踪链路。
- 当正向追踪资源时如果不知道下级资源类型,则需要通过遍历查询所有类型资源再根据 Owner Reference 来进行过滤,这导致计算量偏大且给集群 API 带来比较大的压力。
应用资源的级联关系往往就是我们排查应用故障/配置错误时的链路,如果你的 Kubernetes 经验无法建立起这样的链路,排查 Kubernetes 应用的故障将非常困难。比如 HelmRelease,一旦遇到故障,或许我们需要去查看 Chart 的定义源码才能知道其会产生哪些下级资源,这个门槛可能会阻碍 90% 的开发者用户。
在 Kubernetes 中或许不遵循 Owner Reference 的级联关系资源类型非常多且还在继续增长,因此我们需要让系统具备学习能力来加快正向查询和适配不遵循 Owner Reference 的资源。
apiVersion: v1
kind: ConfigMap
metadata:
name: clone-set-relation
namespace: vela-system
labels:
"rules.oam.dev/resources": "true"
data:
rules: |-
- parentResourceType:
group: apps.kruise.io
kind: CloneSet
childrenResourceType:
- apiVersion: v1
kind: Pod
上面是一个配置用例,告知系统 CloneSet 资源向下级联了 Pod 资源,系统则将从 CloneSet 所在 Namespace 中去查询满足 Owner Reference 条件的 Pod,使查询复杂度为 O(1),每一个规则定义一个父级类型向下关联的多种资源类型,这种方式称为静态配置学习。我们需要实现更多的规则:
比如我们思考,如果我们需要关注 Service 是否正确关联了 Pod,PVC 是否正确的关联了 PV ,这些资源间都不存在 Owner Reference 过滤规则,如果仅配置类型是不够的,我们还需要有过滤条件,比如通过标签,名称等。目前 KubeVela 这部分逻辑是内置了部分规则。除此之外,为了简化用户配置静态学习规则的负担,我们计划实现动态学习能力,基于当前集群所有的资源类型,系统可以动态分析某一个类型的资源作为了哪些类型资源的 Owner,学习成果规则可以共享使用。
资源状态和关键信息
如果仅有资源关系,还不能解决我们的困难,我们还需要能够将异常直接体现出来,让开发者可以在排查错误时具有 O(1) 的复杂度。不同的资源其状态计算略有不同,但一般资源状态中都具有代表其最终状态的 Condition 字段。以此为基础再加上特定资源的状态计算方法形成资源状态计算逻辑,我们将资源状态分为正常,进行中和异常,在拓扑图中分别以蓝色,黄色和红色来代表,方便用户分辨。
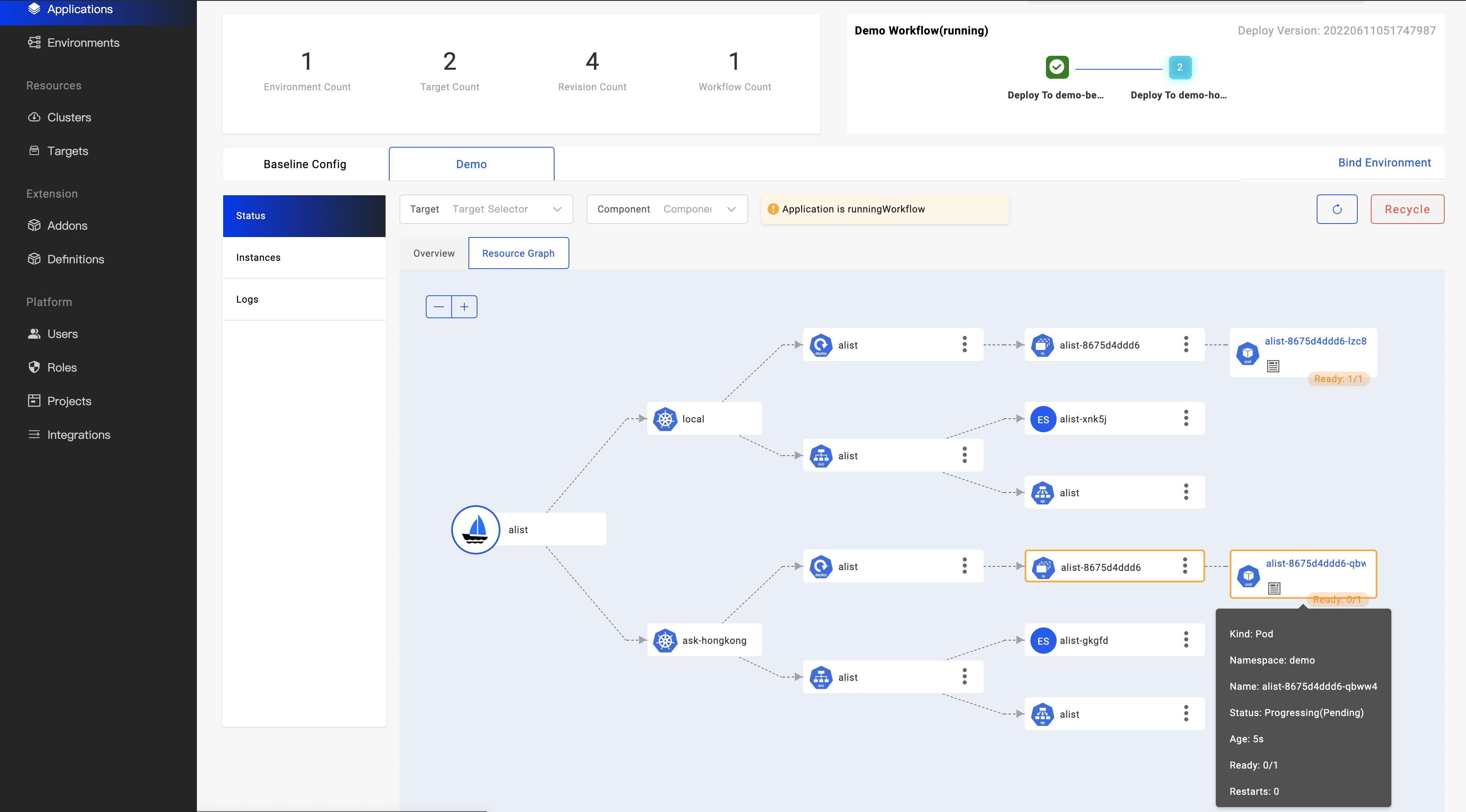
另外不同的资源有不同的关键信息,比如 PVC 是否绑定,Pod 实例使用启动完成,Service 资源是否已关联外网 IP 等等,这些信息我们称为关键信息,对于关键信息通过资源节点挂件或者鼠标移动到其上方时显示。这些信息来帮助用户快速判断该资源的配置是否正确,状态是否正常。
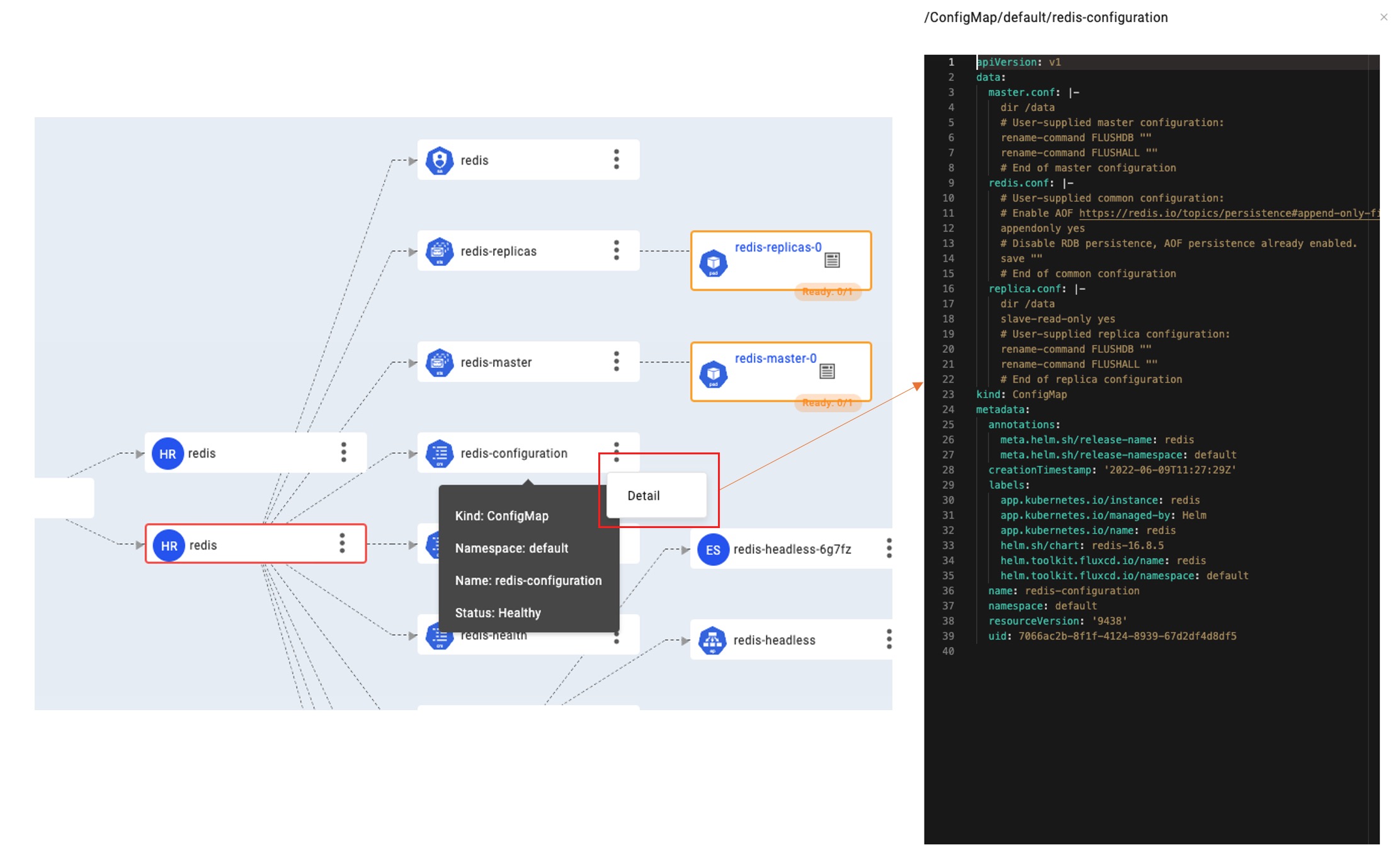
进一步的,如果你希望查询 ConfigMap 详细配置,PersistentVolumes 的容量和访问方式是否正确,RBAC 授权规则是否正确等信息时,你也不需要离开控制台去手动挖掘 Yaml。通过点击节点扩展功能区域的 Detail 按钮发起查询。KubeVela 将通过网关安全地从目标集群中去查询最新的数据状态并展现。
下一步计划
- 更加智能
我们将持续打磨默认规则并通过更多的方式智能判断资源关系图和关键信息,让开发者排查错误时无需过多的经验知识。
- 应用/组件拓扑图
我们目前建立的是底层资源图,这其实不是我们的初衷,我们更希望业务开发者只需要关注应用及包括的所有组件关系和状态,同时结合业务指标分析和监控数据来体现服务的运行压力。
- 更多的运行时
目前建立的资源关系图主要基于 Kubernetes 资源,KubeVela 还有一个核心运行时是云服务平台,我们需要在资源拓扑图中关联到云服务的资源体系。使开发者可以更方便的管理多云应用。