
KubeVela 1.5 于近日正式发布。在该版本中为社区带来了更多的开箱即用的应用交付能力,包括新增系统可观测;新增Cloud Shell 终端,将 Vela CLI 搬到了浏览器;增强的金丝雀发布;优化多环境应用交付工作流等。进一步提升和打磨了 KubeVela 作为应用交付平台的高扩展性体验。另外,社区也正式开始推动项目提级到 CNCF Incubation 阶段,同时在多次社区会议中听取了多个社区标杆用户的实践分享,这也证明了社区的良性发展。项目的成熟度,采纳度皆取得了阶段性成绩。这非常感谢社区 200 多位开发者的贡献。
KubeVela 近一年来发布了五个大版本,每一次迭代都是一个飞跃。1.1 的发布带来了衔接多集群的能力,1.2/1.3 带来了扩展体系和更友好的开发者体验,1.4 引入了全链路安全机制。 如今 1.5 的发布让我们离 KubeVela “让应用交付和管理更轻松”的愿景更近了一步。一路走来,我们始终遵循同样的设计理念,在不失可扩展性的基础上构建自动化处理底层差异化基础设施复杂性的平台,帮助应用开发者低成本从业务开发升级为云原生研发。技术上则围绕从代码到云、从应用交付到管理的完整链路,基于开放应用模型(OAM)提炼衔接基础设施的框架能力。如图 1 所示,如今的 KubeVela 已经覆盖了从应用定义、交付、运维、管理全链路的能力,而这一切能力都基于 OAM 的可扩展性(即 OAM Definition)插件式地衔接生态项目实现。本质上,每一个 Definition 都是将一项具体能力的使用经验,转化为一个可复用的最佳实践模块,通过插件打包实现企业共享或者社区共享。
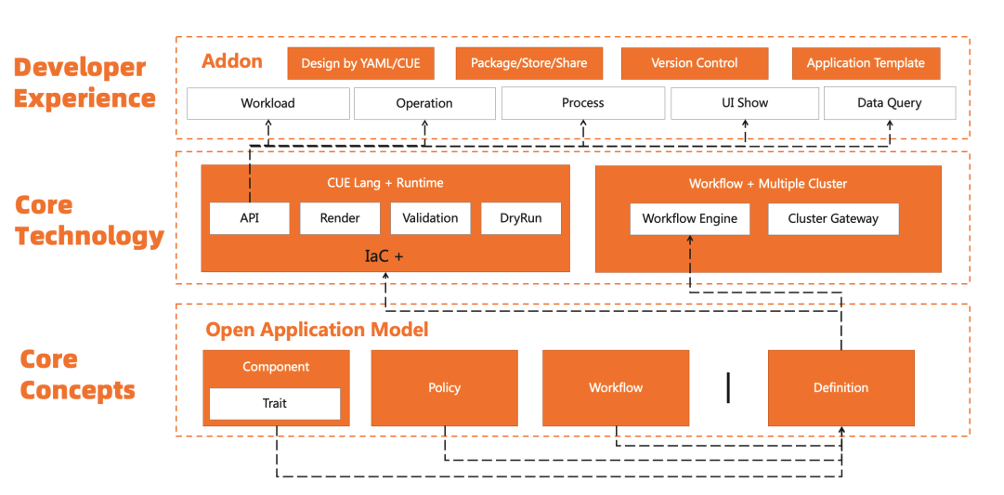 图1 KubeVela 扩展性的核心结构
图1 KubeVela 扩展性的核心结构
云原生领域的原子能力百花齐放既是宝贵的财富,同时也提升了从业门槛。平台构建者需要学习大量的开源项目,聚合多个领域的经验。这往往会花费几个月甚至更长的时间才能构建起企业云原生支撑平台。然而往往搭建的平台将复杂性直接传递给了应用开发者,使其也得学习大量的额外知识。 KubeVela 的设计理念和已有技术成果或许可以帮助到你快速进入云原生世界。KubeVela 在 1.5 版本以及之前数个版本中重点打磨的插件集成规范和统一应用交付体验,有效的解决了云原生领域的原子能力离散问题。
插件规范升级,更灵活的定义方式
KubeVela 插件机制从 1.2 版本发布以来,广受社区用户喜爱,社区插件仓库中已存在近 50 款插件。有近 50 位开发者参与了插件的贡献。
详见:https://github.com/kubevela/catalog
从 1.5 版本开始,插件开发者可以获得更优的体验。从插件定义,分发到可视化管理都全面提升。开发者除了可以使用 YAML 方式来定义插件以外,如果希望更灵活的组合插件包括的资源和更高级的参数化控制,开发者可以完全使用 CUE 来完成插件的定义。目前插件定义的规范包括以下几部分:
- template.cue 或者 template.yaml 结合 resources 目录来定义插件的运行时,例如扩展一个工作负载需要在背后运行的 Operator 等。这一部分不是必须的,例如一些轻量级插件可以没有背后的运行时或者复用其他运行时。通过 YAML 和 CUE 结合的配置方式可以覆盖大多数需求场景。
- definitions 目录,存放 Definition 定义,这是插件的核心部分,定义了该插件扩展的能力如何被用户使用。
- schema 目录,用来辅助 Definition,定义相关 Definition 在 UI 侧的自定义渲染规则。
- views 目录,存储 VelaQL 的语法定义,用来扩展 VelaQL 的查询能力。
- metadata.yaml 与 readme.md,插件元数据定义文件,描述该插件的基础信息和环境需求。 具体规范详见文档:http://kubevela.net/zh/docs/platform-engineers/addon/intro
这里以集成 Helm Chart 包交付能力为例。目前社区中像 FluxCD 或 ArgoCD 项目都提供了部署 Chart 包的原子能力,他们的实现方式不同,各有优势。那么对于 KubeVela 的用户来说可以通过插件引入这个两个项目。如图 2 所示我们需要为终端用户定义一个标准的 API,根据企业实际情况向终端用户暴露必要的参数。
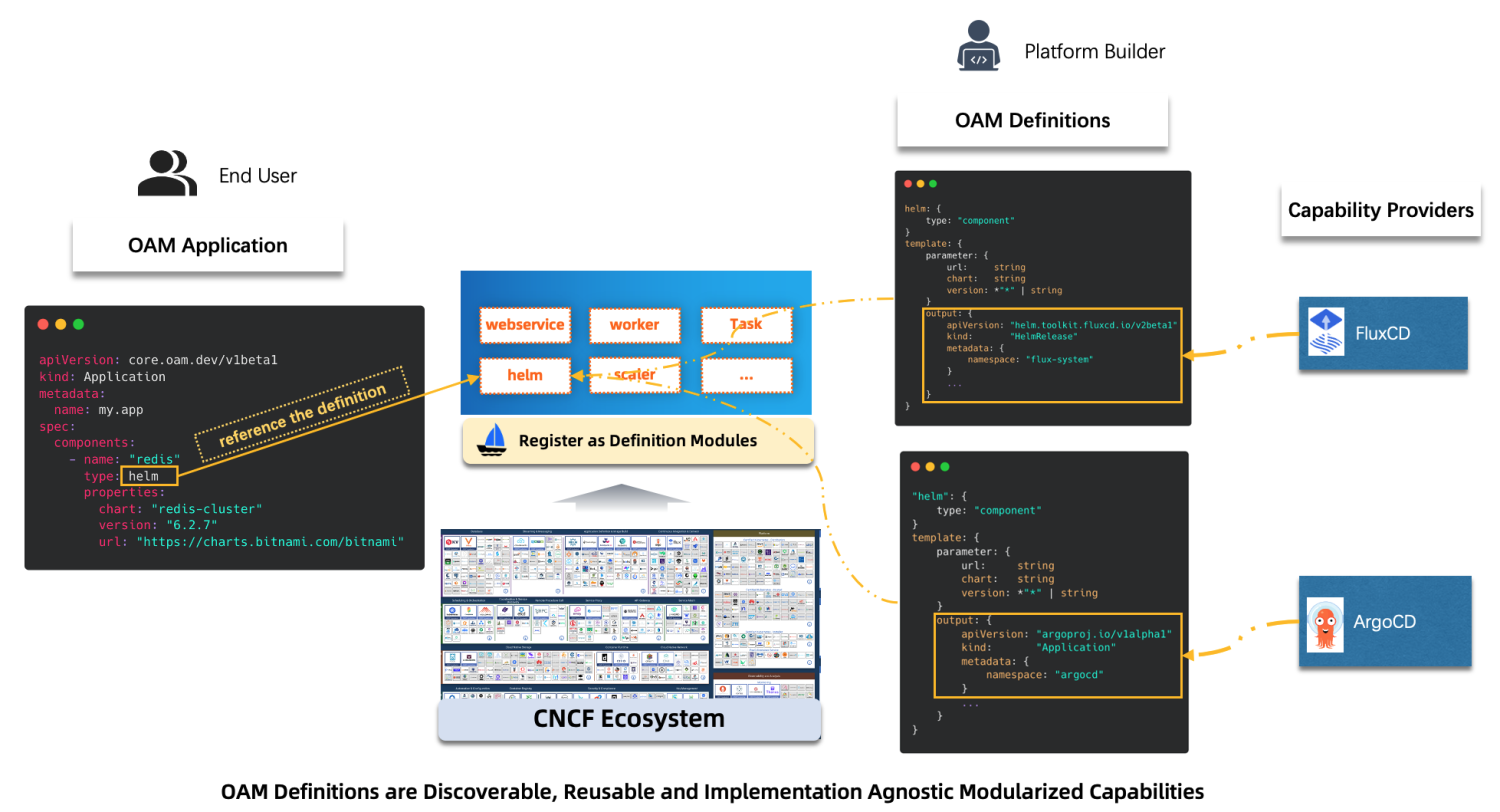 图2 KubeVela 扩展 Helm Chart 包的流程
图2 KubeVela 扩展 Helm Chart 包的流程
如图 3 所示,根据标准的 API,前端 UI 即可自动生成对应的交互页面帮助终端用户便捷简单的完成 Helm Chart 包部署。平台侧根据用户的输入参数和插件定义自动生成底层能力的驱动配置,并智能获取相关状态反馈给用户。这些都是基于插件规范来描述,例如集成 FluxCD,该项目包括了多个控制器提供不同的原子能力,首先我们通过 template.cue 来定义FluxCD 的部署方式,基于不同的参数输入选择部署不同的组件。再通过 definitions 和 schema 目录来定义用户体验。
详细参考:https://github.com/kubevela/catalog/tree/master/addons/fluxcd
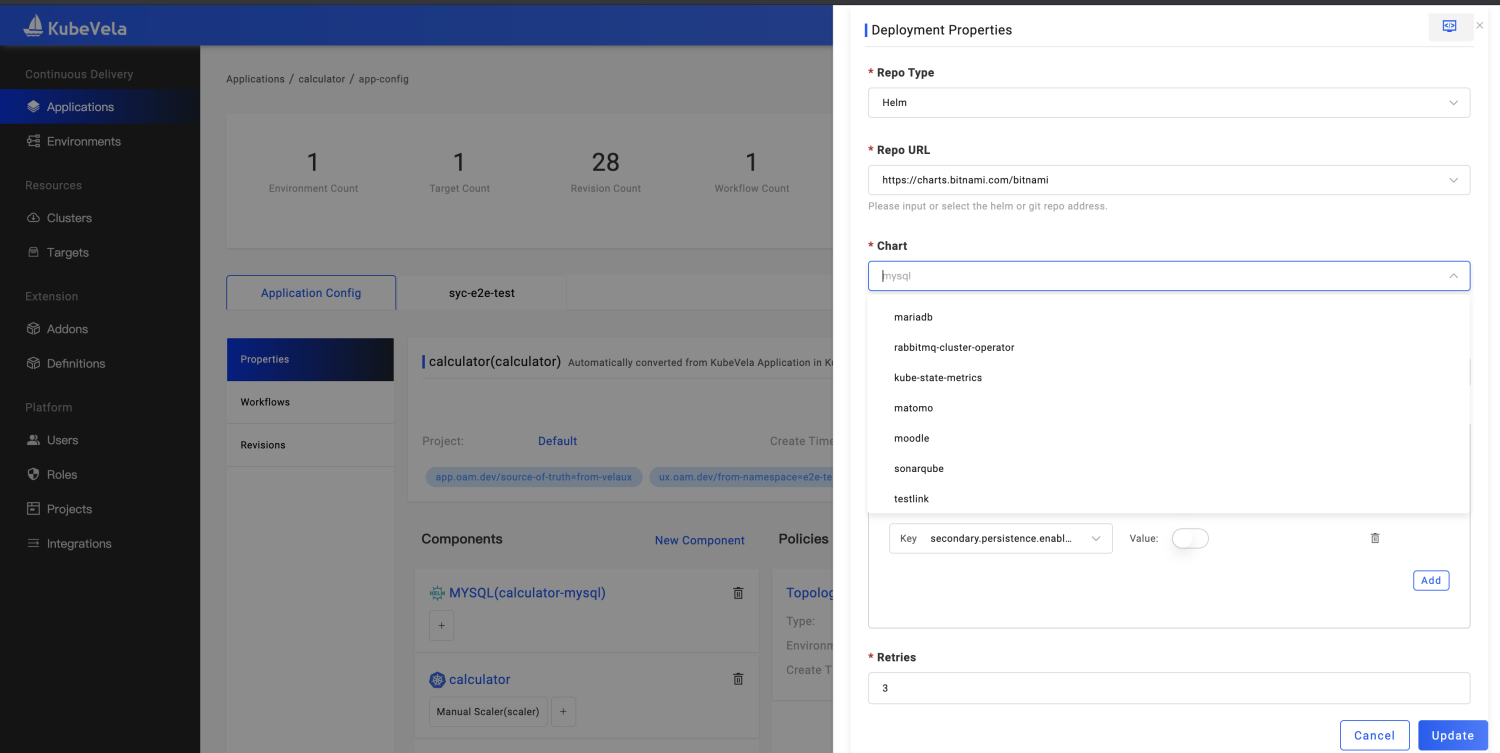 图3 KubeVela 交付 Helm Chart 包的交互
图3 KubeVela 交付 Helm Chart 包的交互
基于插件扩展的功能解读
Telemetry 集成 Prometheus + Grafana + Exporters 支撑系统可观测
应用可观测体系与应用发布关系紧密,一个好的应用可观测体系可以使得应用可靠性管理变得容易。KubeVela 社区将应用可观测列入核心 Feature。社区在 1.5 版本中首先选取了 KubeVela 系统本身的可观测作为案例进行体系能力的研发。目前实现了以下几个要点:
- 多集群可观测基础设施通过插件一键安装,我们首先围绕着 Prometheus + Grafana + Exporters 的方案形成了可观测插件集。面向不同的基础环境便捷安装基础能力。
- 支持一键开启多集群 Metrics 数据汇聚,采用 Thanos Query 方案实现多集群指标聚合查询和可视化。类似的方案将逐步覆盖 Logger 和 Tracing 维度。
- Grafana IaC 化。将 Grafana 的数据源,大盘等配置通过应用模型进行描述,创新性得使用扩展 API 轻量的将 Grafana API 变成了 KubeVela 可以操作的运行时。
- Grafana 大盘自动生成,用户可以通过启用 Grafana 插件即可自动生成 KubeVela 的系统可观测大盘,如图4 所示为 KubeVela 系统运行指标的大盘。该大盘即通过 IaC 体系自动生成,用户只需要启用对应的插件即可。
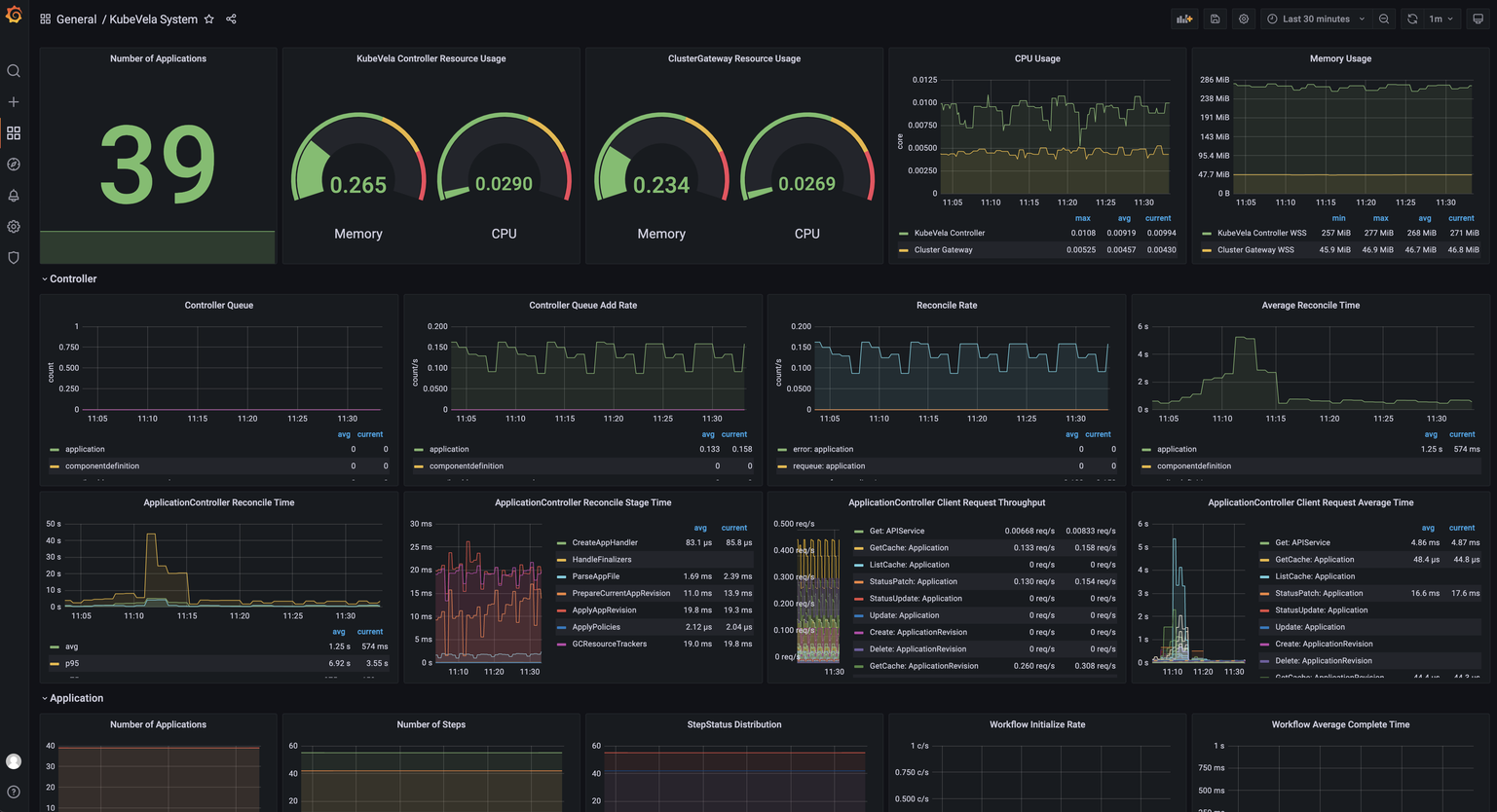 图4 KubeVela 系统可观测大盘
图4 KubeVela 系统可观测大盘
如图 5 所示为接入 KubeVela 的 Kubernetes API Sserver 服务的监控大盘。通过插件向所有子集群下发Exporter,将数据向各集群的 Prometheus 服务暴露,然后汇聚到管控集群进行集中可视化。花一份时间完成 N个集群的监控数据和大盘接入。
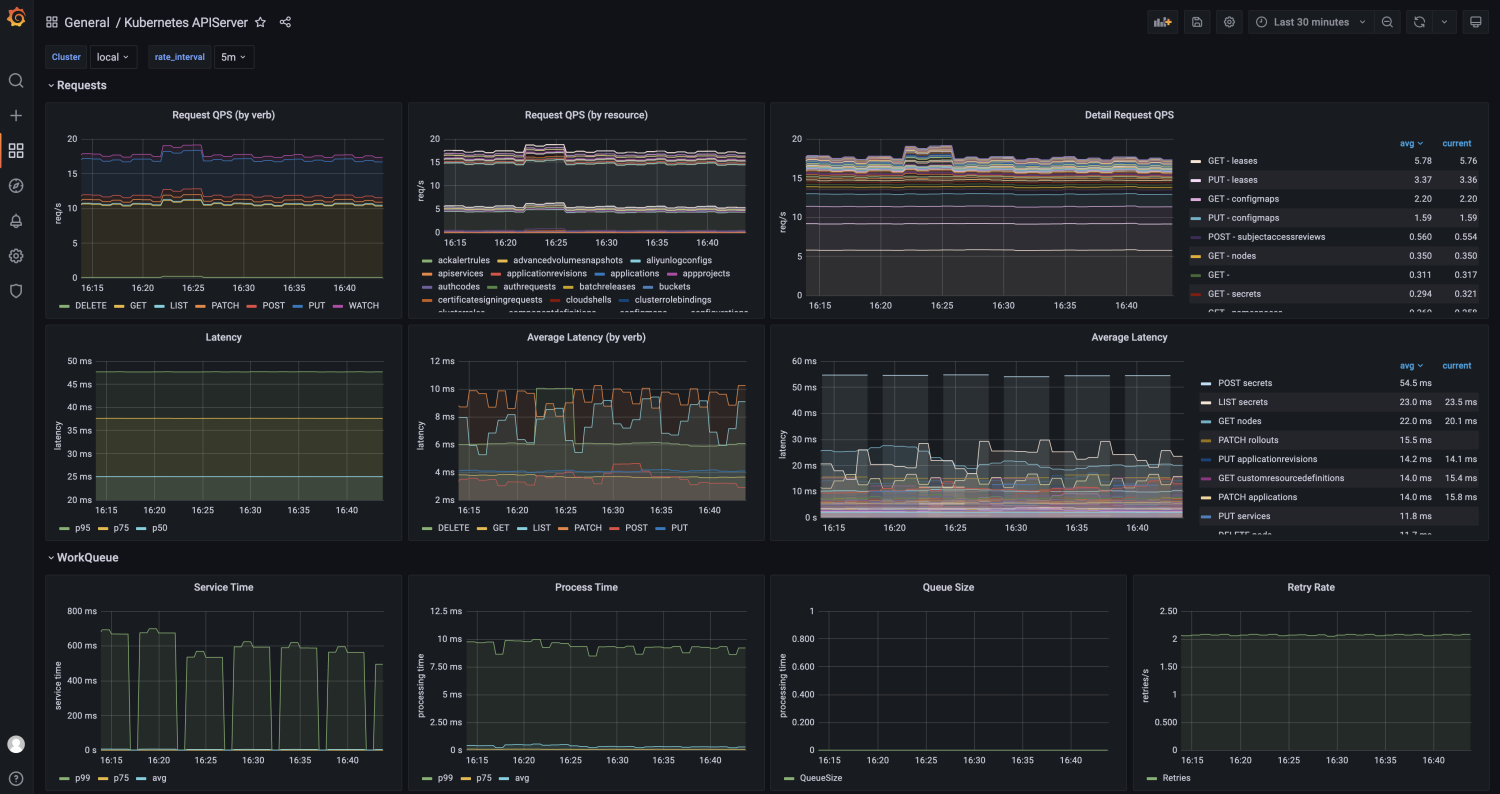 图5 KubeVela 多集群 API 观测大盘
图5 KubeVela 多集群 API 观测大盘
在接下来的版本中,社区将逐步将应用可观测的统一描述和交付融入应用交付过程。覆盖 Metric,Logger 和 Tracing 的数据获取,中间处理和传输,存储和分析,报警和可视化以及应用于应用发布流水线全链路。 参考文档:http://kubevela.net/docs/platform-engineers/operations/observability
集成 Cloud Shell 实现 CLI & UI 协同应用交付
通过 CLI 黑屏的方式操控应用交付的优势在于便捷、批量化和易复制,开发者尤其喜欢。通过 UI 的方式交付应用交互更加优雅,流程性的操作有利于降低学习成本,实现更严格的企业安全控制。可视化程度高可以更好的掌握应用,随时随地进行相关操作。过去的版本中 KubeVela 在 CLI 和 UI 两个维度上存在差异化大,数据不互通的问题。如果两种终端方式可以有效结合可以使应用交付和管理更加顺畅。在 1.5 版本中,KubeVela 引入了 CloudShell 插件,该插件为 UI 用户提供了 Web Shell 终端,统一的入口很好的解决了 CLI 和 UI 割裂的问题,同时带来了更多的能力。针对该流程主要变更如下:
- 开箱即用的工具集;不同于其他平台主要提供进入应用运行空间的 Web Shell 能力。CloudShell 为每一个用户生成一个终端环境,包括了 Vela,Kubectl 等 CLI 工具,在同一个环境中即可管理多个应用。
- 自动完成授权;用户无需关心如何分配 KubeConfig,系统自动根据 UI 用户所拥有的权限完成黑屏环境授权,实现了基本的白屏和黑屏的权限一致化。
- 环境自动回收;每一个用户的终端环境最长存活时间为 1 小时,过期后自动回收防止过多的资源消耗。
- 增强 Vela CLI 能力;重新实现了 log,status,exec,port-forward 等用于 Debug 应用的操作命令,针对应用下差异化工作负载实现了无缝兼容,让用户无感知的可以完成相关操作。无论是基础的 Deployment 资源还是 Helm 打包的负载资源集,亦或者是自定义的 Operator 驱动的工作负载。Vela 都可以自动发现命令相关的底层操作对象。
- 数据自动同步;CLI 可以创建更新应用,变更会同步的 UI 上进行可视化,直到用户选择通过 UI 来接管应用和后续的发布。
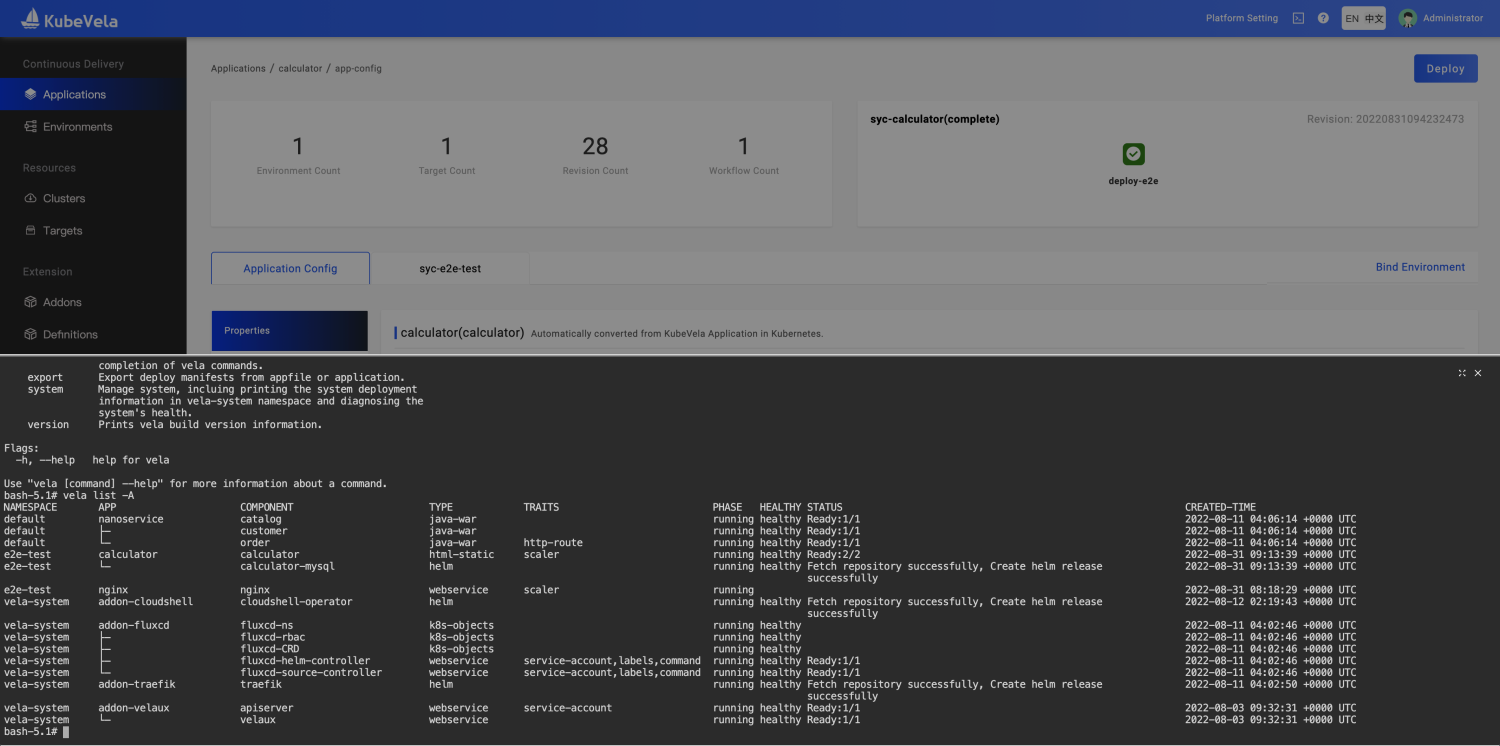 图6 KubeVela CloudShell 操作终端
图6 KubeVela CloudShell 操作终端
集成 OpenKruise Rollout 提供金丝雀发布能力
KubeVela 社区在早期孵化了 Rollout 项目,与 Argo Rollout 的实现模式类似,以一种新的工作负载的形式工作,主要实现了分批发布的能力。随着社区发展,KubeVela 更聚焦于应用全局管控层和插件化扩展能力。因此工作负载层面的 Rollout 实现转移到了 OpenKruise 社区,在双方的共同努力下实现了可以针对原生 Deployment,StatefulSet 以及 OpenKruise 扩展的工作负载 CloneSet 多种工作负载的金丝雀发布能力。同时与 KubeVela 中的 Helm 交付模式共存时,可以实现针对 Helm Chart 包应用无需做任何变更即可进行金丝雀发布,这在业内具有创新性,对于用户非常便捷。Kruise Rollout 作为一个插件集成到了 KubeVela 生态。KubeVela 用户仅需要启用 插件,即可在应用组件中配置 Rollout Trait。同时可以与组件的 Gateway,HTTPRoute 等网关规则 Trait 实现协同。 整理下来,该实现有以下几项优势:
- 无侵入,无绑定;通过旁路的方式引入 Rollout 能力,用户无需对已有应用配置进行其他变更,引入成本低且随时可以移除;
- 易于使用;仅需要简单的配置流量切换规则,结合 KubeVela 的 UI 可视化,可以有效观测 Rollout 过程中的副本数量变化以及引入的额外资源关系;
- 兼容性好;不管用户使用了什么工作负载进行包装(Helm 或 自定义 Operator),Rollout 可以发现现底层的负载资源后以旁路形式工作。
参考文档:http://kubevela.net/docs/end-user/traits/rollout
VelaUX 增加多环境差异化可视化配置
VelaUX 至推出开始就具有了多环境部署能力,直到 1.5 版本,支持了用户可视化编辑多环境的差异化,从而真正匹配了用户多环境应用发布的需要。用户可以添加 Override Policy 配置,可以做到环境,集群或 Namespace 多个维度的差异化。应用的基准配置和差异化的配置统一管理。 如图5 所示,应用策略 Policy 已内置了多种可选项,包括差异化配置;应用多集群策略;应用维持策略和GC策略等等。通过 UI 的引导可以方便用户根据需要配置对应的策略。
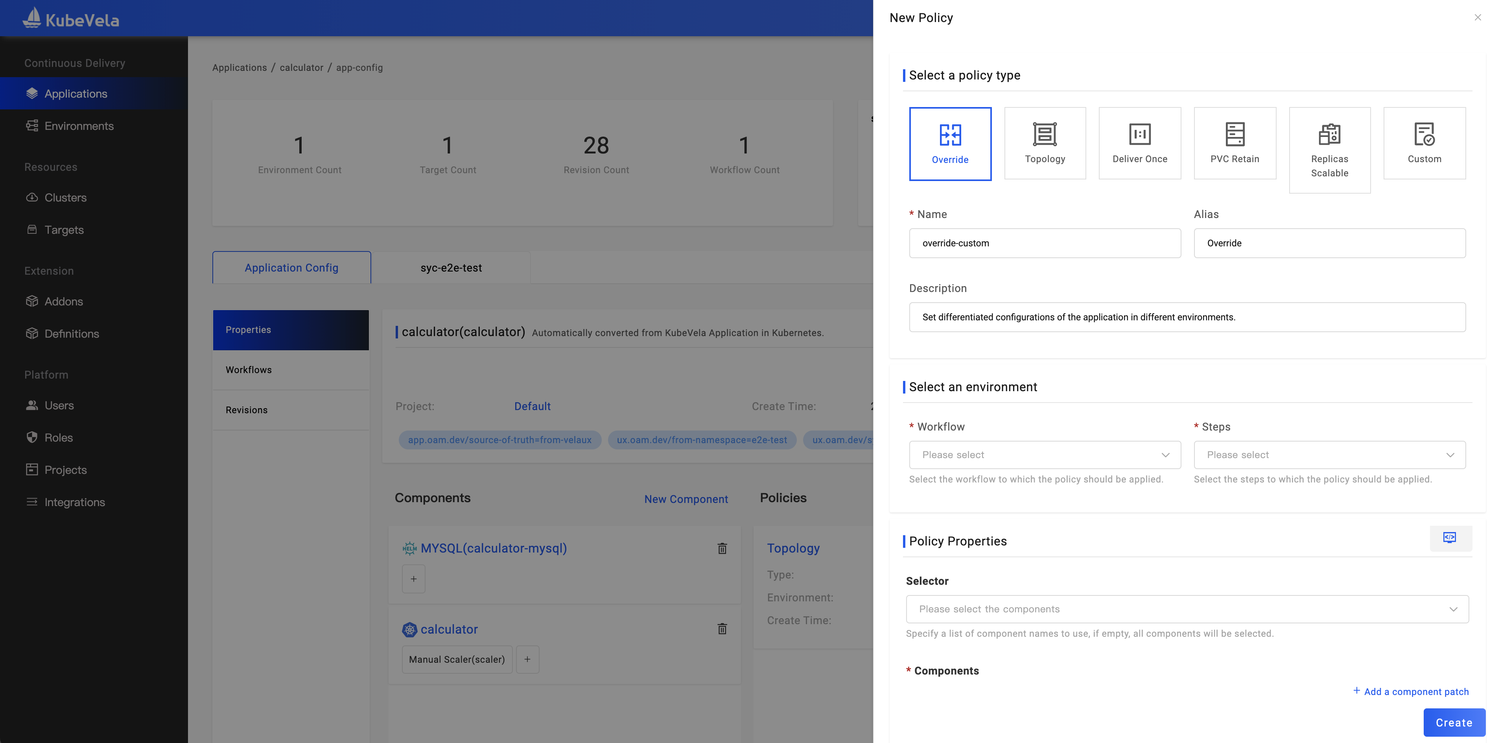 图7 KubeVela Policy 新增/编辑窗口
图7 KubeVela Policy 新增/编辑窗口
在1.5 版本中,针对不同的环境部署前后新增了以下便捷功能:
DryRun(试运行)能力;用户可以在部署一个环境之前选择先进行 DryRun,通过 UI 反馈的结果评估应用配置是否符合预期,防止部署后才发现错误配置影响线上服务稳定性。
环境差异洞察;切换到不同环境视图时自动进行本地配置与部署配置的比对,如果出现差异将提示用户并展示出差异的配置项。防止出现配置漂移或计划进行上线的配置忘记上线等。
版本详情查询和差异比对;通过版本管理页面,可以查看每一个版本的应用配置渲染结果,也可以将版本配置与当前运行配置或最新的本地配置进行比对。方便用户追踪配置变更过程。
参考文档:http://kubevela.net/docs/tutorials/multi-env
应用引擎能力提升
除了上述的插件能力提升以外,在应用引擎方面也进行了大量的更新。其中性能优化提升明显,工作流执行时 CPU 消耗降低 75%。并行执行的数量显著提升。下面列举了以下重要的变更:
- Workflow 新增超时控制,在 Workflow 步骤中配置超时时间,当执行时间大于超时时间后 Workflow 将结束变为终止状态。
- Workflow 新增条件判断,在 Workflow 步骤中配置 If 字段,支持从 status 或 input 中读取数据进行判断以确定当前步骤是否需要执行。同时支持 If Always 机制,支持有些步骤需要在任何情况下执行的场景。
- Workflow 支持显示切换模式,支持 DAG 或者默认的 StepByStep。
- 新增共享资源策略,不同应用可以描述相同的资源,例如命名空间或者ConfigMap,设置为共享资源即不会冲突。
- 优化应用资源树构建算法,提升了在不同场景下的查询效率,更易于扩展自定义规则,同时增加了部分默认规则。
更多变更内容请参考:https://github.com/kubevela/kubevela/releases/tag/v1.5.0
结语
整体来说,随着 1.5 版本的发布,KubeVela 在产品能力,社区生态,标杆用户等多个维度都取得了显著进步。用户案例囊括了金融,智能制造,互联网等多个行业。我们也期待更多的用户可以分享你的实践经验,帮助 KubeVela 社区找到更准确的前进道路。在 1.6 的版本计划中,将带来更完善的应用可观测能力;独立于应用的工作流能力,衔接多个应用的持续发布控制和与可观测系统的协同。有相关需求和想法的开发者可以随时参与到社区讨论之中。