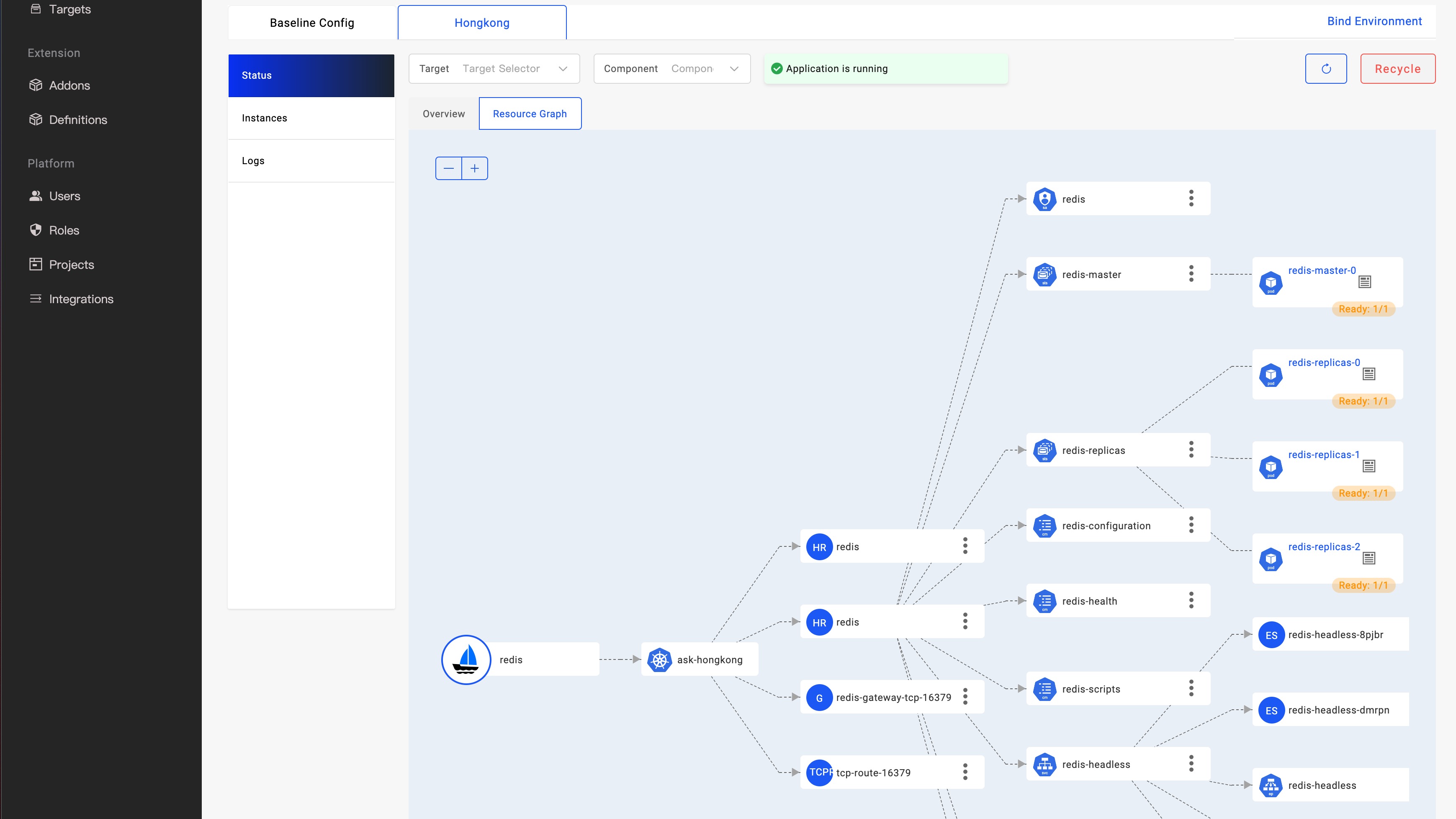
KubeVela 1.5 was released recently. This release brings more convenient application delivery capabilities to the community, including system observability, CloudShell terminals that move the Vela CLI to the browser, enhanced canary releases, and optimized multi-environment application delivery workflows. It also improved KubeVela's high extensibility as an application delivery platform. The community has started to promote the project to the CNCF Incubation stage. It has absorbed the practice sharing of multiple benchmark users in many community meetings, which proves the community's healthy development. The project is now mature to some extent, and its adoption has made periodical achievements, thanks to the contributions of more than 200 developers in the community.
KubeVela 1.5 released, the Flexible Selection of CNCF Atomic Capabilities to Build a Unique Enterprise Application Release Platform
· 13 min read
KubeVela Team